
[Feature Selection] #1. 다양한 Feature Selection method 소개
Feature Selection Methods
오랜만에 블로그 포스팅이다! Kaggle이나 공모전, 대학원 프로젝트에서 모델링을 할 때 가장 막막했던 부분은 feature engineering 파트이다. 모델의 성능 향상에 기여하는 feature를 생성하는 것도 중요하지만,
이와 못지 않게 필요한 feature만 선택하여 모델링 과정에서 computation cost를 줄이고 해석의 용이성을 높이는 feature selection 도 매우 중요하다.
모델링을 할 때, feature가 너무 많아지면 차원의 저주(Curse of dimensionality) 문제가 발생할 수 있다. 차원의 저주는 간단하게 말하면 학습 변수(=feature)의 수가 너무 많아져 모델링 및 데이터의 처리에 문제가
생기는 것을 말한다. 이 문제를 피하기 위해 target value 예측에 기여를 하는 feature만 고르는 과정이 필요한데, feature selection이 이 과정을 수행하는 단계라고 보면 될 것이다!
이번 포스팅에서는 대표적인 feature selection 방법들에 대해 설명하고, Kaggle의 House price 데이터에 적용하는 내용을 다룰 것이다.
Feature selection method는 크게 다음의 세 타입으로 나눌 수 있다. 이 세가지 method에 속하는 대표적인 feature selection 기법에 대해 알아보도록 하겠다!
- Filter’s methods
- Wrapper’s methods
- Embedded methods
1. Filter’s methods
Filter’s method는 세 가징 method 중 가장 심플하다고 말할 수 있는 방법으로, 일변량 통계량(univariate statistics)을 이용해 feature의 특성을 추출하고 선택하는 방법이다. 다른 변수들과의 관계성은 고려하지 않고 단일 변수를 통계량을 이용해 평가하기 때문에 다른 methods에 비해 계산량과 시간이 적게 소모된다는 장점이 있다. 또한 모델 학습 없이 feature selection을 할 수 있는 방법이다.하지만 Filter’s methods의 경우 다른 변수와의 상관관계 등을 고려하지 않기 때문에 다른 wrapper나 embedded methods에 비해 모델 성능이 떨어진다는 단점이 있다. 대표적인 filter’s methods feature selection 방법에는 variance threshold, corrleation coefficient 방법이 있다.
시뮬레이션을 위해 House price 데이터를 이용한다. 이 포스팅에서는 간단한 방법론 설명만 할 것이기 때문에 편의를 위해 object 변수는 제거하였다. 그리도 missing value는 각 변수의 mean으로 impute 했다.
(1) Variance Threshold
Variance threshold는 말 그대로 변수의 variance가 지정한 threshold 보다 작으면 drop하는 방법이다. 변수의 variance가 너무 작으면 target을 예측하는 성능이 낮아진다고 판단하는데, 어떤 변수의 variance가 작으면 변수의 각 value가 target에 미치는 영향의 차이는 미비하기 때문이다. 이러한 이유로 feature을 선택할 때 이 방법을 사용하기도 한다.
Variance threshold 기법의 단점은 개별 변수의 variance만 고려한다는 것이다. 예를 들면, 만약 어떤 변수의 variance가 작더라도 target 변수와 상관관계가 높으면 target을 예측하는데 영향을 줄 수 있다. 하지만 variance가 작다는 이유로 이 변수를 제거하면 모델의 성능은 낮아질 것이다. 또한 threshold 설정이 주관적이기 때문에 이 방법 역시 threshold 값에 따라 모델 성능이 달라질 수 있다.
Variance Threshold 기법은 사이킷런 패키지의 VarianceThreshold 를 이용해 구현할 수 있다. () 안에는 기준 threshold를 지정하면 된다.
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(0.8)
train_thresh = selector.fit(train)
(2) Correlation coefficient
이 방법은 매우 간단하다. Target 변수와 개별 feature 변수의 상관계수를 구하고, 상관계수의 절댓값이 큰 feature를 선택하는 방법이다.
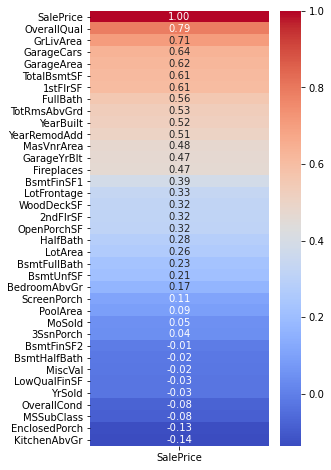
예시를 살펴보자. House Price의 Target 변수는 SalePrice 이다. 여기서 우리는 SalePrice와 다른 feauture들의 상관계수를 구하여 비교한다. 아래는 결과를 히트맵으로 시각화한 것이다. 빨간색 부분은 상관계수가 양수인 부분으로, 위로 갈수록 SalePrice와의 상관관계가 강해진다. 파란색 부분은 상관계수가 음수인 부분으로, 아래로 갈수록 음의 상관관계가 강해진다. 즉, correlation coefficient를 위해 feature를 선택한다면, 빨간색 부분은 위에서부터, 파란색 부분은 아래에서부터 선택한다.
2. Wrapper’s methods
Wrapper’s methods는 filter method와 달리 모델을 학습하면서 feature을 선택하는 과정이다. Feauture을 하나씩 제거하거나 더하면서(쉽게 말하면 모든 feature subset을 하나씩 학습하면서) 가장 성능이 높게 나오는 feature set을 선택하는 방법이 바로 wrapper’s method이다. 이 방법은 Filter’s methods에 비해 computation 양이 많고 시간도 오래 걸린다는 단점이 있지만, 모든 feature subset을 평가하기 때문에 filter’s methods 보다 우수한 성능을 낼 수 있다는 장점이 있다. 대표적인 wrapper’s methods 방법에는 Recursive Feature Elimination(RFE) 가 있다.
(1) RFE
RFE는 전체 feature을 포함하여 모델을 학습하고 이후 feature을 하나씩 제거하면서 가장 성능이 놓은 feature subset을 결정하는 방법이다. 이 방법은 사이킷런 패키지의 RFE 를 이용하여 구현할 수 있다. RFE를 conduct 할 때, n_features_to_select를 지정해준다. 최종적으로 선택할 feature의 수를 결정하는 파라미터이다. 아래 예시에서는 20개의 feature을 선택하도록 설정했다. 그리고
get_support()를 이용하면 어떤 feature가 선택되었는지를 확인할 수 있다. 자세한 코드는 여기에서 확인하면 된다.
rfe = RFE(rf, n_features_to_select = 20)
train_rfe = rfe.fit(X, y)
하지만 RFE에서도 filter’s method와 똑같은 문제에 직면한다. 최종적으로 몇 개의 feature을 선택할지는 매우 주관적이기 때문에 섣불리 결정할 수 없다. 이를 해결하기 위해 사이킷런에서는 RFECV 를 제공한다. 이 패키지는 cross validation을 통해 적절한 feature의 수를 결정한다.
selector = RFECV(rf, step = 1, cv = 3) # step: 테스트 한번마다 몇 개의 feature을 제거할 것인지 지정
selector.fit(X, y)
print(selector.support_) # 선택된 feature 확인(True = 선택, False = 제거)
print(selector.ranking_) # 각 feature의 ranking 확인 - ranking이 1이면 선택되고 그 이외에는 제거된다
3. Embedded methods
Embedded methods는 filter’s methods와 wrapper’s methods를 적절히 혼합한 방법이다. 대표적인 embedded methods에는 tree 기반의 feature importance, L1 및 L2 regularization이 있다.
(1) Feature Importance(트리 기반)
Feature importance는 트리기반 알고리즘을 사용하는 모델에 대해 적용되는 방법이다. 트리기반 모델을 학습하면 각 feature 마다 feature importance를 추출할 수 있는데, 여기서 말하는 feature importance는 information gain과 관련이 있다. 트리 모델은 불순도(impurity)를 최소화 하는 방향으로 분기를 한다. 예를 들어 트리 분기를 할 때, 분기를 할 node를 선택하는데 이 때 information gain을 이용한다. Information gain은 쉽게 말하면 (상위 노드의 불순도 - 분기한 후 좌/우 노드의 불순도) 를 계산한 것으로, information gain이 크면 노드가 분기했을 때 불순도가 많이 감소한다는 것을 의미한다. 요약하면 트리 모델은 information gain이 큰 node를 선택해 그 node를 기준으로 트리를 분기하게 되는 것이다. Feature importance는 해당 feature가 얼마나 불순도를 감소시켰는지를 기준으로 계산된다. 즉, 트리기반 모델에서는 feature가 불순도를 많이 감소시킬수록 importance가 커진다.
Feature selection을 위해 feature importance 방법을 적용하면, feature importance가 큰 변수만을 선택하여 모델을 학습하는 것이다! 하지만 cutoff 기준이 주관적이기 때문에 몇개의 feauture을
선택하느냐에 따라 모델의 성능이 달라진다는 단점이 있다.
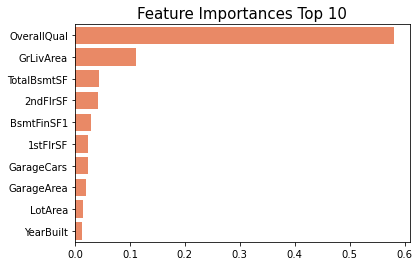
House price 데이터를 RandomForestRegressor로 학습한 후, 가장 feature importance가 높은 top 10개의 변수를 추출하였다. 이렇게 tree 기반 모델을 사용하면 .feature_importances_ 속성을 이용하여 각 변수의 feature importance를 추출할 수 있다.
이번 포스팅에서는 다양한 feature selection 방법에 대해 살펴보았다! 다음 포스팅에서는 요즘 머신러닝에서 핫한 feature selection 방법인 Permutation importance와 SHAP에 대해 포스팅 하겠다! :)
참고문헌
https://www.analyticsvidhya.com/blog/2020/10/feature-selection-techniques-in-machine-learning/
https://subinium.github.io/feature-selection/
댓글남기기