
[Feature Selection] #2. Permutation Importance
※ 이 포스팅은 Interpretable machine learning 을 요약 및 참고를 주로 하였습니다.
Permutation Importance 란?
Permutation Importance(순열중요도) 는 featrue selection 방법 중 하나로, 특정 feature의 importance를 feature를 permutation 했을 때 모델의 에러가 얼마나 커졌는지에 따라 계산하는 방법이다. Permutation importance는 기본적으로 모델을 학습한 후에 계산가능하다.
예를 들어보면 다음과 같다. 한 데이터셋을 변수 A, B, C가 구성한다고 가정하자. 여기서 변수 A의 feature importance는 변수 A에 속하는 값들을 랜덤으로 permutation 했을 때의 모델의 에러와 기존 데이터셋의 모델의 에러의 차이로 계산한다. 만약 변수 A가 target 값 예측에 크게 기여하는 변수라면, 변수 A를 permutation 한 후 모델의 에러는 매우 커질 것이다. 반면, target 예측에 크게 기여를 하지 않는 변수라면 permutation 전후의 모델 에러의 차이가 크게 나지 않을 것이다.
Permutation Importance 의 특징을 간략히 정리하면 다음과 같다.
- 데이터를 모델에 학습한 후에 feature importance를 계산할 수 있다
- 어떤 feature가 모델의 target 변수 예측에 크게 기여할수록 permutation importance가 증가한다
Permutation Importance의 장단점
Permutation importance의 장점 및 단점에 대해 간략히 살펴보자.
(1) 장점
- 한 feature와 다른 feature들의 interaction, correlation을 반영하여 feature importance를 계산한다.
- 다시 변수 A, B, C로 구성된 데이터셋의 예시를 들어보자. 변수 A와 B의 interaction이 매우 크다고 가정해보자.(interaction이 크다는 것은 변수 A 값과 변수 B의 값이 상관관계가 크다는 것) Permutation importance를 구하기 위해 변수 A를 랜덤으로 permute 하면, 변수 A와 B의 상관관계는 깨지게 된다. 변수 A의 값들이 완전히 뒤바뀌어 섞여버렸기 때문이다. 따라서 변수 A의 permutation importance는 변수 A 자체의 importance + A와 B의 interaction effect를 모두 고려하여 계산한 변수 중요도가 된다.
- 모델을 재학습할 필요가 없다.
- 일부 다른 feature selection 방법이 importance를 계산 후 중요하지 않는 feature를 제거하고 모델을 재학습하여 이전 모델과 성능을 비교해야 하는 과정을 거쳐야 하는 것과 달리, permutation importance 방법은 이 과정을 모두 포함하여 importance를 계산하기 때문에 모델의 재학습이 필요하지 않다.
(2) 단점
- Permutation importance는 모델의 해석보다는 모델의 에러를 반영한다.
- 앞서 permutation importance의 원리를 설명했듯이, 이는 모델의 에러가 얼마나 증가했는지를 반영하는 지표이다. 따라서 여기서 얻은 개별 변수의 중요도는, 개별 변수가 모델의 target 변수에 어떤 영향을 미치는지를 해석하는데는 도움이 되지 않는다.
- Permutation을 하면서 비현실적인 데이터 인스턴스를 만들 수 있다.
- 다른 예시를 들어보면 데이터에 키(height) 변수와 몸무게(weight) 변수가 있다고 가정하자. 일반적으로 키와 몸무게는 양의 상관관계를 갖고 있다. 만약 키 변수를 permutation을 랜덤으로 하게 되면 키 2m에 몸무게가 20kg인, 말도 안되는 데이터 인스턴스가 생성될 수 있다. 이러한 비현실적인 인스턴스로부터 얻은 permutation importance는 정확하지 않기 때문에 신뢰할 수 없는 경우가 발생하기 도 한다.
따라서 Permutation importance도 다른 feature selection 방법들과 마찬가지로 데이터를 구성하는 변수들의 관계를 잘 파악하고 상황에 맞게 사용해야 한다.
Simple code for Permutation Importance
파이썬의 eli5 패키지를 이용하면 permutation importance를 쉽게 계산할 수 있다.
Steps for Permutation importance
- 모델링을 위한 데이터 전처리(preprocessing)
- Train, validation, test set 생성하기
- Model을 정의하고 train set으로 학습하기
- Validation set을 이용해 permutation importance 계산
# scoring: 모델 error 계산 metric
# n_iter: iteration 횟수. Permutation importance를 몇 번 iteration을 할 지 결정
perm = PermutationImportance(model, scoring = 'neg_mean_squared_error', n_iter = 5, random_state = 0).fit(X_val, y_val)
# permutation importance 계산 결과 출력
eli5.show_weights(perm, feature_names = X_val.columns.tolist())
Kaggle의 house price 데이터를 적용하여 permutation importance를 구하면 다음과 같이 결과를 출력할 수 있다.
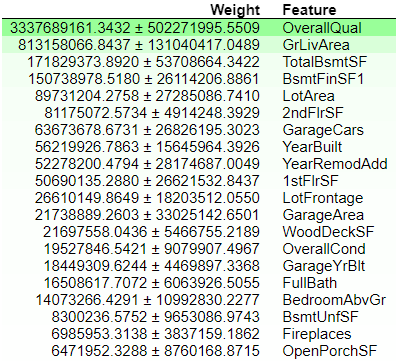
이번 포스팅에서는 Permutation importance에 대해 간단히 살펴보았다. 다음 포스팅에서는 요즘 머신러닝에서 가장 많이 쓰이는 SHAP에 대해 다룰 예정이다!
참고문헌
https://www.kaggle.com/dansbecker/permutation-importance
https://christophm.github.io/interpretable-ml-book/feature-importance.html
댓글남기기