
[Feature Selection] #3. SHAP
Feature selection 시리즈 포스팅의 마지막! 이번 포스팅에서는 Kaggle과 같은 데이터분석 플랫폼에서도 많이 쓰이는 SHAP에 대해 다룬다.
Introduction to SHAP
SHAP 은 머신러닝에서 feature의 영향/효과를 계산할 때 사용하는 방법으로, 게임이론에 등장하는 shapley value를 바탕으로 목적변수에 대한 각 feature의 영향이 측정된다. 이전 포스팅에서 다룬 Permutation importance와 다른 점은, permutation importance는 모델의 성능이 얼마나 떨어지는지에 따라 변수 중요도를 측정하고 feature을 선택하지만 SHAP은 변수가 목적변수에 미치는 영향을 기준으로 선택한다.
1. Shapley value
SHAP에 대해 이해하기 위해선 게임이론의 shapley value에 대한 이해가 선행되어야 한다. Shapley value의 기본 아이디어는 모든 변수 조건 조합에서 특정 변수가 미치는 영향(marginal contribution)을 측정하는 것이다! 말로만 설명하면 이해하기 어렵기 때문에 간단한 예시와 함께 살펴보자.
Example: Hotel price
호텔 가격을 책정하는데 다음과 같은 요소들이 고려된다고 가정하자: 주변에 공원 여부, 면적 100, 3층, 반려동물 허용 여부
여기서 우리는 반려동물 허용여부가 목적변수인 호텔 가격에 미치는 영향을 측정하는 것이 목표이다. ‘반려동물 허용여부’를 제외한 다른 변수들은 다음과 8개의 경우로 조합될 수 있다.
- no feature
- 주변 공원여부
- 면적 100
- 3층
- 주변 공원여부, 면적 100
- 주변 공원여부, 3층
- 면적 100, 3층
- 주변 공원여부, 면적 100, 3층
8가지의 변수 조합 각각으로부터 ‘반려동물 허용여부’가 호텔 가격에 미치는 영향의 marginal contribution을 계산하여 가중평균을 내면 최종적인 ‘반려동물 허용여부’의 영향을 계산할 수 있다.
이 포스트에서는 자세한 수식은 설명하지 않겠다. Shapley value에 대한 자세한 수식은 이 링크를 참고하면 된다.
2. SHAP
Shapley value에 대해 알아봤으니 이제 본격적으로 SHAP에 대해 알아보자! 데이터를 SHAP을 적용했을 때 얻을 수 있는 그래프와 그 해석에 대해 중점적으로 알아볼 것이다. 사용한 데이터는 이전 포스팅들과 마찬가지로 Kaggle의 House Price 데이터를 간단하게 가공해서 사용하였다.
Python에서 SHAP을 구현하기 위해서는 pip install shapley를 통해 해당 패키지를 먼저 설치해줘야한다. 그 후 import shap 을 이용해 SHAP을 구현하기 위한 함수, 메소드를 불러온다.
SHAP에서 지원하는 feature 관련 그래프는 다음과 같다.
- Feature importance plot
- Summary plot
- Dependence plot
- Force plot
- Decision plot
이제 5가지의 그래프를 어떻게 구현하는지, 어떻게 해석할 수 있는지에 대해 하나씩 설명해보도록 하겠다.
Global한 해석이 가능한 그래프들
(1) Feature importance(변수중요도)
앞서 다루었던 tree 기반 feature importance, permutation importance와 마찬가지로 SHAP에서도 feature importance를 추출할 수 있다. SHAP에서의 feature importance는 앞서 설명했듯이, 각 feature의 shapley value의 가중평균으로 계산한다. SHAP에서의 변수중요도는 summary_plot 으로 그래프를 그릴 수 있다. 우선 트리기반모델인 RandomForestRegressor을 사용했기 때문에 model에 shap.TreeExplainer을 적용한 후 X_train 데이터를 기반으로 shap_value를 추출한다. 그리고 summary_plot에서 plot_type = 'bar'로 지정하면 우리가 흔히 그리는 feature importance plot을 그릴 수 있다.
model = RandomForestRegressor(n_estimators = 200, max_depth = 10, random_state = 0)
model.fit(X_train, y_train)
shap_imp = shap.TreeExplainer(model).shap_values(X_train)
shap.summary_plot(shap_imp, X_train, plot_type = 'bar')
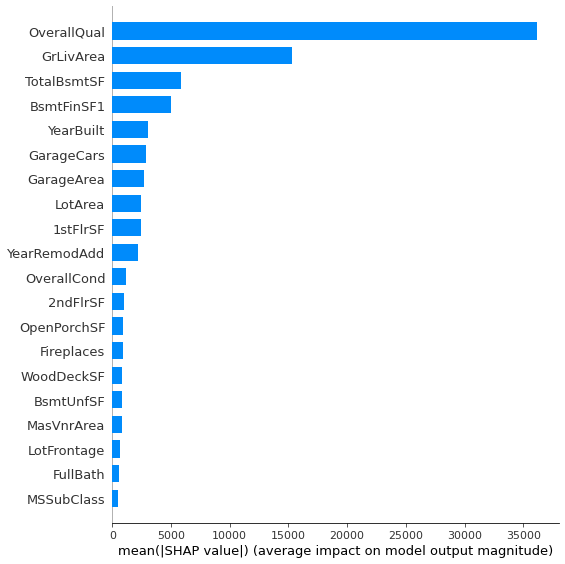
[해석]
- 각 변수의 SHAP 변수 중요도를 알 수 있다.
- 개별 변수의 변수 중요도는 파악할 수 있지만, target value와 어떤 관계가 있는지는 파악하기 힘들다.
(2) Summary plot
Feature importance를 통해 개별 변수의 중요도는 알 수 있지만, target과의 관계성은 파악하지 못한다는 단점이 있다. 이를 보완한 것이 SHAP의 summary plot이다. 말로 설명하는 것 보다 그래프로
보는것이 더 이해가 잘 되니, 그래프를 해석하면서 그래프의 특징을 살펴보겠다.
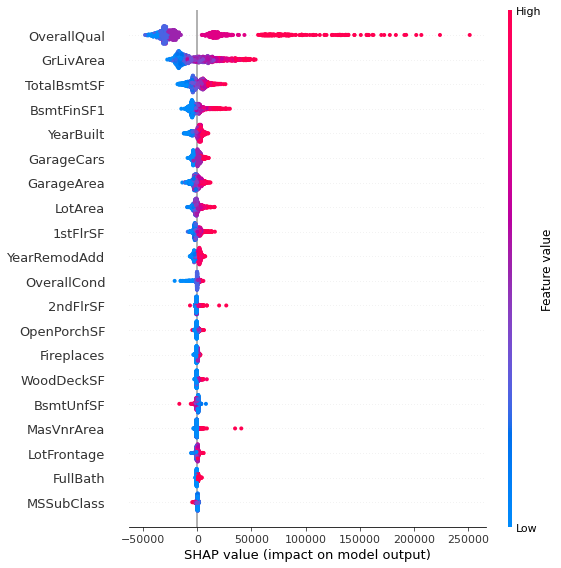
[해석]
- $x$축: SHAP value, $y$축: 각 feature(위에서부터 변수중요도가 큰 feature)
-
빨간색
: 큰 feature 값, 파란색 : 작은 feature 값
- 예를 들어, OverallQual의 경우 feature value가 큰 값들의 SHAP value가 크다. 즉, feature와 target이 양의 상관관계를 가진다는 것을 알 수 있다. 반대로 BsmtUnfSF는 feature 값이 크면 shap value가 작아져 feature과 shap value가 음의 상관관계를 이룬다.
이처럼 summary plot을 이용하면 각 feature가 target value와 어떤 상관관계가 있는지 쉽게 확인할 수 있다. Feature와 target의 상관관계 해석의 용이성이 summary plot의 장점이다!
(3) Dependence plot
Dependence plot은 두 가지 정보를 한번에 나타낼 수 있는 그래프이다. 대신, dependence plot을 그릴 때 하나의 feauture을 지정해줘야 한다.
Dependence plot을 통해 얻을 수 있는 정보는 2가지가 있다.
- feature와 target의 상관관계(positive/negative 여부)
- feature와 interaction이 가장 큰 변수와의 관계(자동적으로 interaction이 가장 큰 변수를 선택해준다)
GrLivArea 변수에 대한 예시를 살펴보자. SHAP 패키지에서는 dependence_plot 함수로 구현할 수 있다. Input으로는 해당 변수, 계산한 shap values, base data를 넣어주면 된다.
shap.dependence_plot('GrLivArea', shap_imp, X_train)
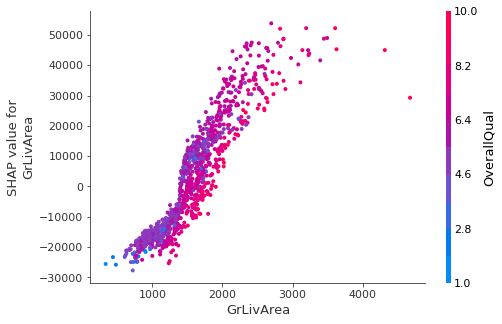
[해석]
- GrLivArea와 target value는 양의 상관관계를 갖고 있다.(x축과 왼쪽 SHAP value 축 참고)
- GrLivArea와 가장 interaction이 많은 변수는 OverallQual이다. 빨간색에 가까울수록 OverallQual 값이 크고 파란색에 가까울수록 작아진다. 이 점에 착안하여 그래프를 보면 빨간색으로 표시된 값들에 해당하는 GrLivArea 값이 크기 때문에 GrLivArea와 OverallQual은 양의 상관관계를 가진다.
Local한 해석이 가능한 그래프들
(4) Force plot
Force plot은 머신러닝 모델을 local하게 해석할 수 있는 그래프 중 하나이다. Force plot을 이용하면 개별 데이터에서 각 feature가 target에 어떤 영향을 줬는지를 해석할 수 있다. 이 그래프를 그릴 때는 전체 row를 사용하는 것이 아니라, 한 개의 row만 사용하여 개별 데이터와 모델의 관계를 해석한다. 아래 코드와 같이 21번째 row에 속하는 데이터만을 이용해 force plot을 그린다.
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_val)
shap.force_plot(explainer.expected_value, shap_values[20,:], X_val.iloc[20,:])
[해석]
- 굵은 글씨로 써있는 숫자는 해당 데이터의 target 값을 나타내고, base value는 X_val에 속하는 target value의 평균을 나타낸다.
-
빨간색
은 target 변수의 값을 높게 만드는 feature들을 나타내고, 파란색 은 반대로 target 변수의 값을 낮게 만드는 feature들을 나타낸다. feature이름 옆에 써있는 숫자는 해당 데이터의 feature의 값을 나타낸다.
- Positive/negative impact 여부를 확인하기 위해서는 각 feature의 평균과 비교를 해야 한다. 예를 들어, GarageArea 값은 720이고 평균은 470 인데, 평균보다 GarageArea의 값이 크면 House Price가 높아지므로 GarageArea는 House price에 positive한 영향을 준다고 해석할 수 있다. 반대로, 어떤 변수 A의 값이 A의 평균보다 낮은데 target 값이 높아졌다면, 변수 A는 target에 negative한 영향을 미치는 것이다. 이렇게 평균과 일일히 비교해아 하는 것이 force plot의 단점이다.
(5) Decision plot
Decision plot은 force plot과 마찬가지로 local한 해석이 가능한 그래프이며, force plot의 단점을 보완한 그래프이다. Force plot의 경우 개별 feature가 target에 어떤 영향을 주는지를 해석할 수 있다. decision_plot 함수를 이용하여 그래프를 그릴 수 있다.
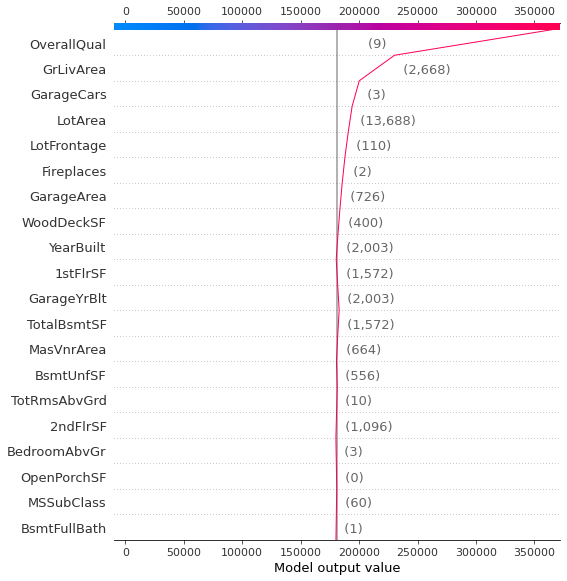
shap.decision_plot(explainer.expected_value, shap_values[50,:], X_val.iloc[50,:])
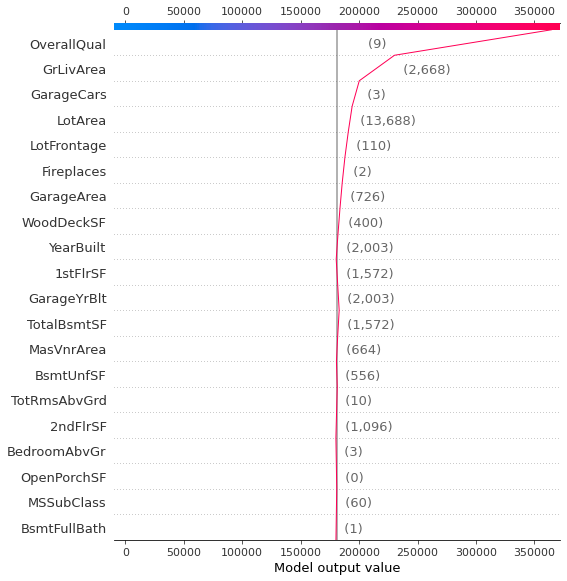
[해석]
- 회색 수직선은 RandomForestRegressor 모델의 base 값이다.
- 괄호안에 써진 숫자는 개별 데이터의 feauture가 값는 값이다.
- 빨간선은 SHAP value를 나타낸다. 즉 feature 중요도를 나타내는 것인데, 아래에서부터 시작해 누적하여 맨 위로 가면 최종적으로 개별 데이터의 target value에 도달한다(상단 바에 있음).
- 해당 feature에서 빨간선이 왼쪽으로 가면 이 feature가 target value에 negative impact를 주는 것이고 오른쪽으로 가면 target에 positive한 impact를 준다고 해석할 수 있다.
그리고 force plot과 달리 decision plot에서는 여러개의 데이터를 한꺼번에 plot할 수 있다.
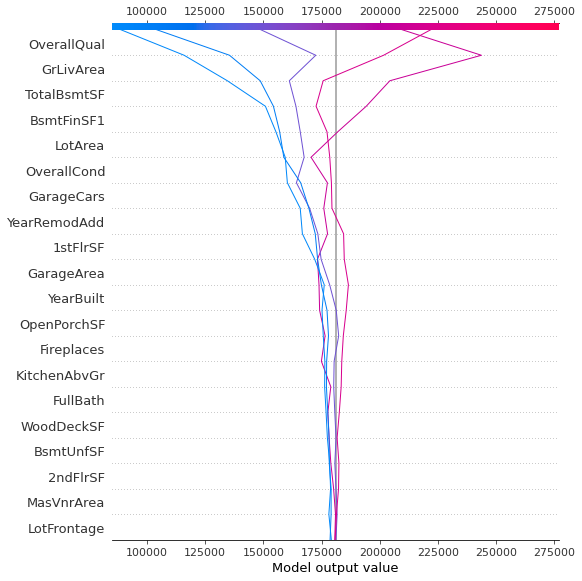
위 그래프와 같이 개별 데이터가 target value를 얻기까지 각 feature가 어떤 영향을 미치는지를 한눈에 파악할 수 있다.
Decision plot를 통해 오늘 포스팅한 내용 말고도 clustering, cumulative importance 등 다양한 정보를 얻을 수 있다. 오늘은 기본적인 그래프의 특징과 해석을 소개하는 포스팅이니 생략했지만, 기회가 되면 더 깊은 내용도 다루도록 하겠다.
이렇게 feature selection 및 해석 포스팅의 대장정이 끝났다! 이제 다양한 데이터에 공부한 내용들을 적용하는 연습을 하면 될 것 같다 :)
참고문헌
https://towardsdatascience.com/introducing-shap-decision-plots-52ed3b4a1cba
https://towardsdatascience.com/explain-your-model-with-the-shap-values-bc36aac4de3d
댓글남기기