
[Time Series Analysis] #5. Simple Prophet Model: 주식데이터 적용
내 깃허브 블로그 첫 포스팅은 주식데이터의 탐색에 관한 내용이었다. 오늘은 첫 포스팅에서 썼던 미래에셋 주식 데이터 중 ‘삼성전자’의 주가를 Prophet 이라는 시계열분석 모델을 이용해 fit 하고 prediction도 해보는 포스팅을 해볼까 한다.
Preview
Prophet 모델이란?
Prophet은 페이스북에서 개발한 시계열 예측 모델이다. 지금까지 시계열분석 관련 공부 포스팅을 해오면서 시계열 데이터 예측에 쓰이는 다양한 모델과 기법들에 대해 공부했는데, 이 모델들과
비교했을 때 Prophet이 가지는 장점은 이렇다.
1) ARIMA/ARMA와 같이 정상성 여부를 확인하지 않아도 된다. 즉, 비정상성 시계열이어도 별다른 변환을 하지 않아도 된다.
2) Holiday(연휴,휴일)을 추가하여 holiday에 따라 달라지는 데이터의 값을 반영할 수 있다.
3) 파라미터들이 직관적이고, 한 번 보고 이해하고 구현하기 쉽다.
(이외 Prophet에 대한 자세한 설명은 https://facebook.github.io/prophet/ 를 참고하자) 이러한 장점들로 인해 시계열 예측을 할 때 Prophet 모델을 점점 많이 사용하고 있는 추세이다!
사용 데이터
Prophet 모델에 사용한 데이터는 2020 미래에셋 금융빅데이터 페스티벌에서 제공한 stocks.csv 중 삼성전자에 해당하는 데이터를 사용했다. 삼성전자 주식 데이터의 트렌드 그래프는
[첫 포스팅]에 들어가면 볼 수 있다!
삼성전자 주가 데이터는 2019년 7월 1일부터 2020년 7월 28일까지의 주가를 포함하고 있다. 그리고 주식 거래가 이루어지지 않는 주말과 공휴일의 날짜는 포함되지 않는다.
Prophet Modeling with steps
이제 본격적으로 Prophet 모델링을 해보자! 모델링 전, 데이터를 정제해야하는데 Prophet 모델의 input 데이터는 ‘ds’ 라는 날짜 값을 가지는 변수, ‘y’라는 예측해야 하는 변수를 포함해야 한다. 즉, 본 데이터에서는 ‘ds’는 2019.7.1 ~ 2020.7.28 를, ‘y’는 보통 주가의 기준이 되는 ‘종목종가’가 된다. 이제부터 이 데이터셋을 df라고 칭한다.
Model 1: Basic Prophet model
Model 1은 아무런 파라미터 처리를 하지 않은 기본값으로 세팅된 Prophet 모델이다. 코드로는 다음과 같이 구현하면 된다.
model1 = Prophet() # baisc prophet model
model1.fit(df)
forecast = model1.predict(df)
Model 1을 이용해 df 데이터를 fit 한 결과는 아래와 같다. Model 1을 쓰면 대략적인 주가 데이터의 추세는 반영하지만, 급격히 감소하거나 증가하는 구간의 값들을 잘 반영하지 못한다.
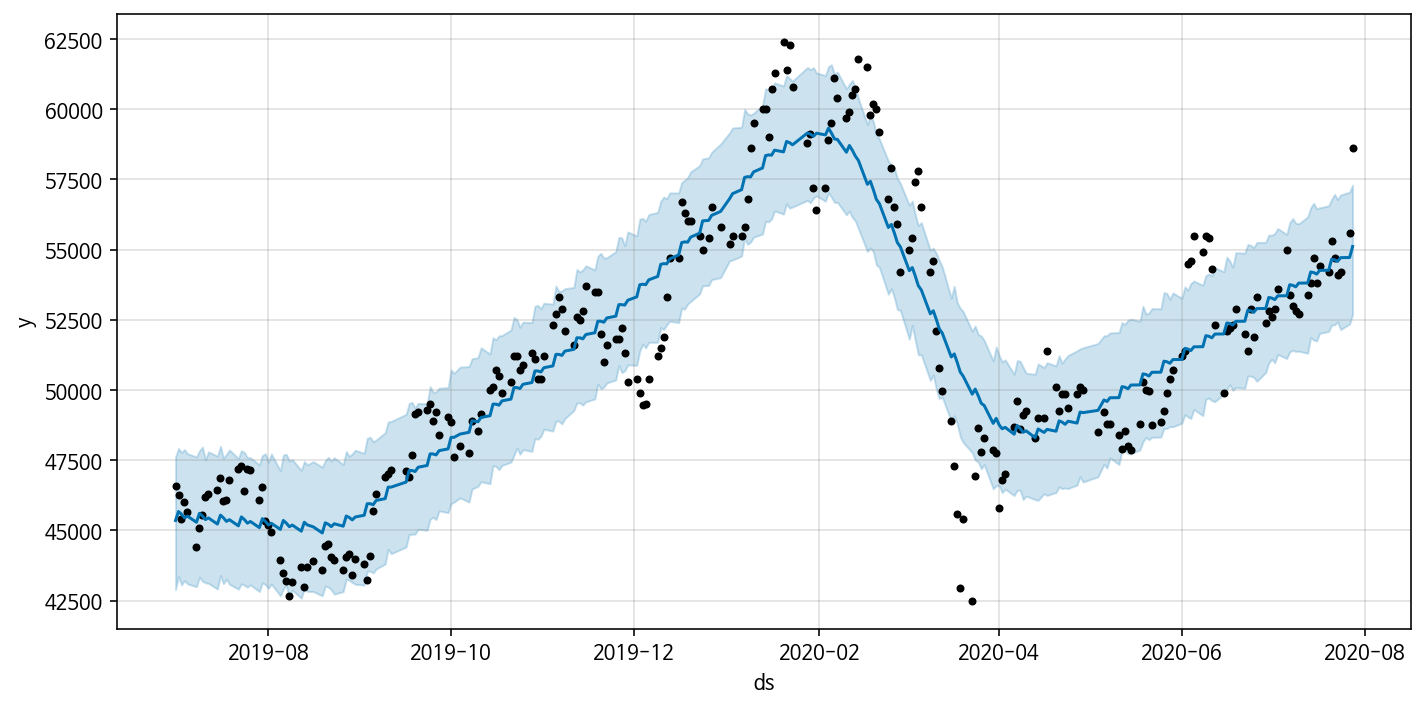
Model 2: Add Trend change points
Model 1은 전반적인 트렌드는 반영하지만, 세부적인 데이터의 트렌드(증감 부분 등등)을 잡아내지 못하는 경향이 있다. Prophet 모델에서는 trend change points 라는 것을 조정함으로써 트렌드를 좀 더 세부적으로 반영할 수 있다. Change point라는 것은 데이터의 트렌드가 변하는 지점을 말한다(예를 들면 상승->하락 지점). 기본적인 파라미터는 다음과 같다.
changepoint_range: 앞에서부터 몇 %의 데이터에서 change point를 지정할지를 선택하는 파라미터다. 예를 들어, 0.8이면 앞에서부터 80% 만큼의 데이터에서 change point를 잡는다. 이 파라미터를 너무 높게 잡으면 기존 데이터의 트렌드를 과하게 반영해 future 데이터를 예측할 때 overfitting이 발생할 수 있다.chagepoint_prior_scale: change point의 유연성을 결정하는 파라미터이다. 이 파라미터의 값을 늘릴수록 유연성이 높아지는데, 유연성이 높아진다는 것은 데이터의 트렌드를 더 유연하게 잡아낸다는 뜻이다. 너무 작은 값이면 underfitting의 위험이 있지만, 너무 크게 잡으면 overfitting 위험이 있다.
Model 1의 changepoint_range은 기본값인 0.8, 그리고 chagepoint_prior_scale 은 0.05로 설정되어있다. 하지만 Model 1은 데이터에 underfit 하는 경향을 보이므로 changepoint_prior_scale을 0.2로 높였다.add_changepoint_to_plot을 이용하면 잡아낸 change point를 반영한 그래프를 보여준다.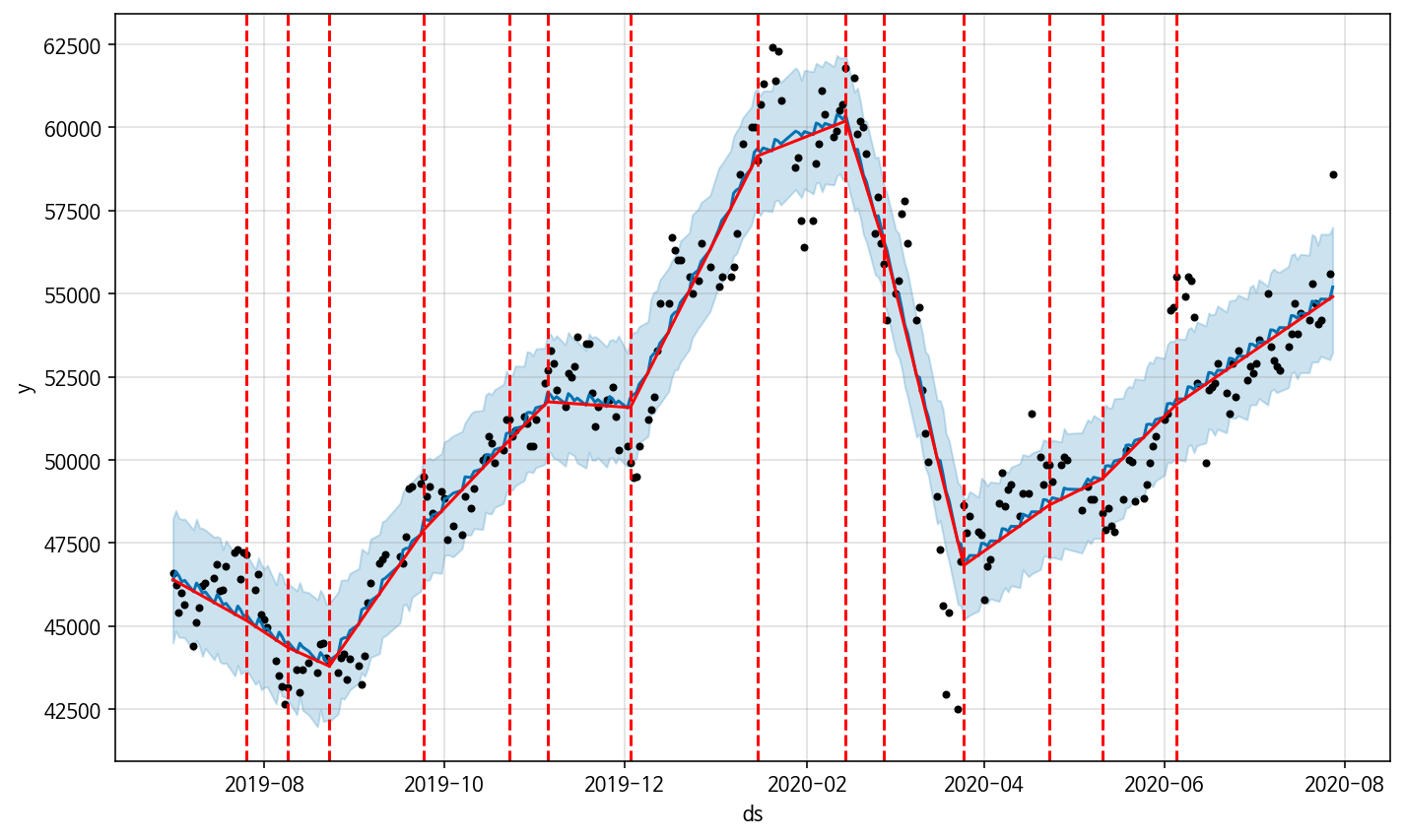
완성된 Model 2의 모형의 코드는 이렇다!model2 = Prophet(changepoint_range=0.8, changepoint_prior_scale= 0.2)Model 2를 이용해 fit한 결과는 아래와 같다. Model 1에 비해 세부적인 추세는 잘 반영하나, 아직도 몇몇 구간에서는 트렌드를 반영하지 못한다.
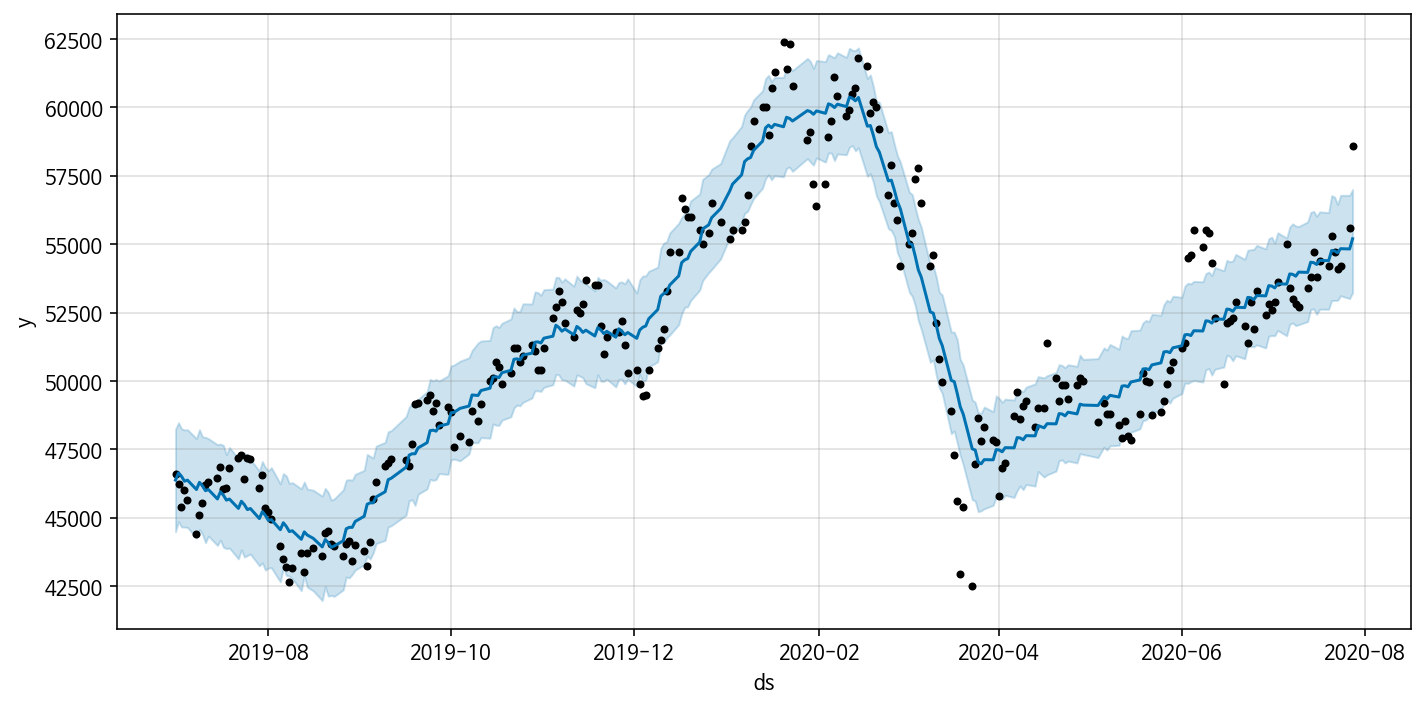
Model 3: Add monthly seasonality
Model 1과 Model 2에서는 오로지 weekly seaonsality 만을 반영한다. 하지만 삼성전자의 월별 평균 주가를 비교했을 때, 월별로 차이가 다소 극명했다. 따라서 Model 2에 monthly seasonality를
반영하도록 설정해준다. Prophet 모델에는 monthly seasonality를 파라미터로 지정할 수 없기 때문에 add_seasonality 를 이용해 직접 지정해줘야한다! period에는 30일과 31일의 평균인 30.5 를 지정하겠다.
model3 = Prophet(changepoint_range=0.8, changepoint_prior_scale= 0.2)
model3.add_seasonality(name='monthly',period=30.5,fourier_order=5)
Model 3를 이용해 df를 fit하면 확실히 Model 1과 Model 2에 비해 2020년 2월 부근에서의 급락, 2019년 12월에서의 감소 추세를 잘 반영한다. 즉 Model 2보다도 세밀하게 삼성전자 주가 데이터의 트렌드를 잡아낸다. 하지만 여전히 감소구간(2020년 2월, 2020년 4월 부근)에서의 데이터의 트렌드는 반영하지 못한다.
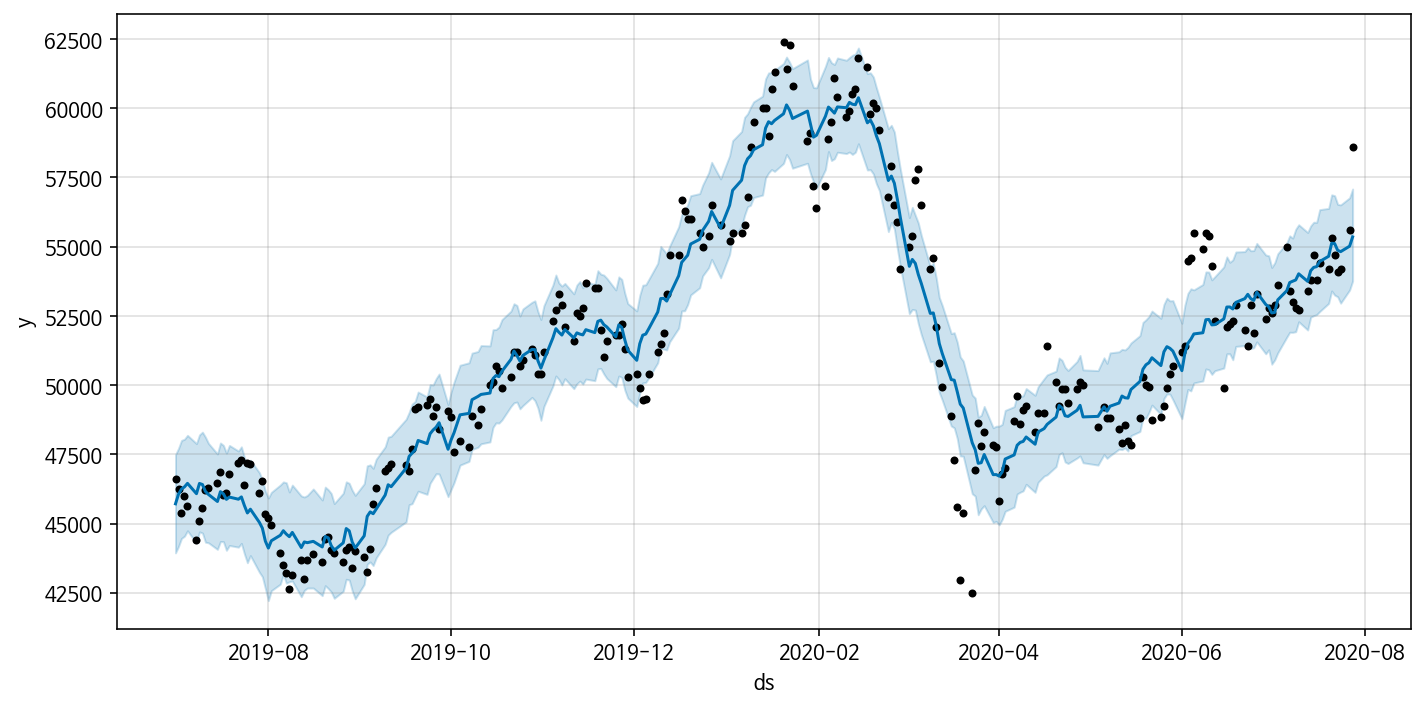
Model 4: Multiplicative seasonality
Model 3에서의 fitting 결과에 아직도 아쉬움이 남아 overfitting 일 수 있지만, 삼성전자 주가 데이터 트렌드를 좀 더 정확하게 반영하기 위해 seasonality를 multiplicative로 설정했다. 이전 시계열분석 포스팅에서 다뤘는데, 데이터의 진폭이 시간에 따라 일정하지 않고 증가하거나 감소하면 multiplicative seasonality의 성질을 가지고 있다고 한다. 삼성전자 주가 데이터의 진폭 역시 시간이 지날수록 어느정도 증가하는 경향을 보이기 때문에 seasonality를 multiplicative로 설정해주었다.
model4 = Prophet(changepoint_range=0.8, changepoint_prior_scale= 0.3, seasonality_mode='multiplicative')
model4.add_seasonality(name='monthly',period=30.5,fourier_order=5)
그 결과 감소구간(2020년 2월, 2020년 4월 부근)를 비롯해 전반적인 데이터의 트렌드를 제일 정확하게 반영해낸 것을 볼 수 있다!
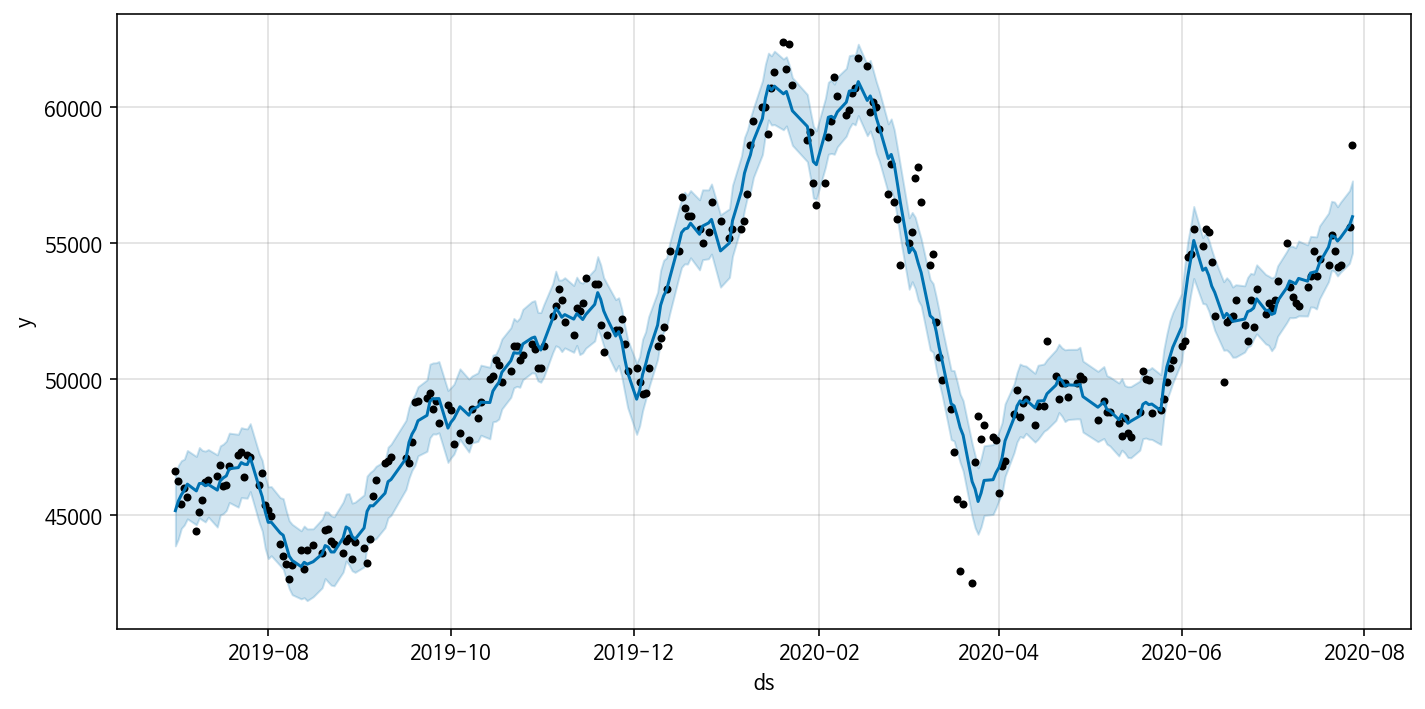
Evaluation
Prophet 모델이 전반적인 데이터의 트렌드를 정확하게 반영할수록 좋은 모델이라고 생각할 수 있다. 물론 어느정도 맞는 말이지만, future data를 예측할 때 기존 데이터를 너무 정확하게
반영하게 되면 overfitting이 발생하며 future data 에 대한 prediction 값들과 실제 값 사이의 오차가 크게 될 수 있다.
앞서 만든 Model 4개에 대해 train set(2019년 7월 1일 ~ 2020년 6월 30일) 에 model을 fitting한 후 test set(2020년 7월 1일 ~ 2020년 7월 28일)를 예측하여 성능을 비교해보자. 성능 평가를
위한 metric으로는 MAE(mean absolute error)와 RMSE(root mean square error)을 사용하였다. 예측 plot은 다음과 같이 그릴 수 있다.
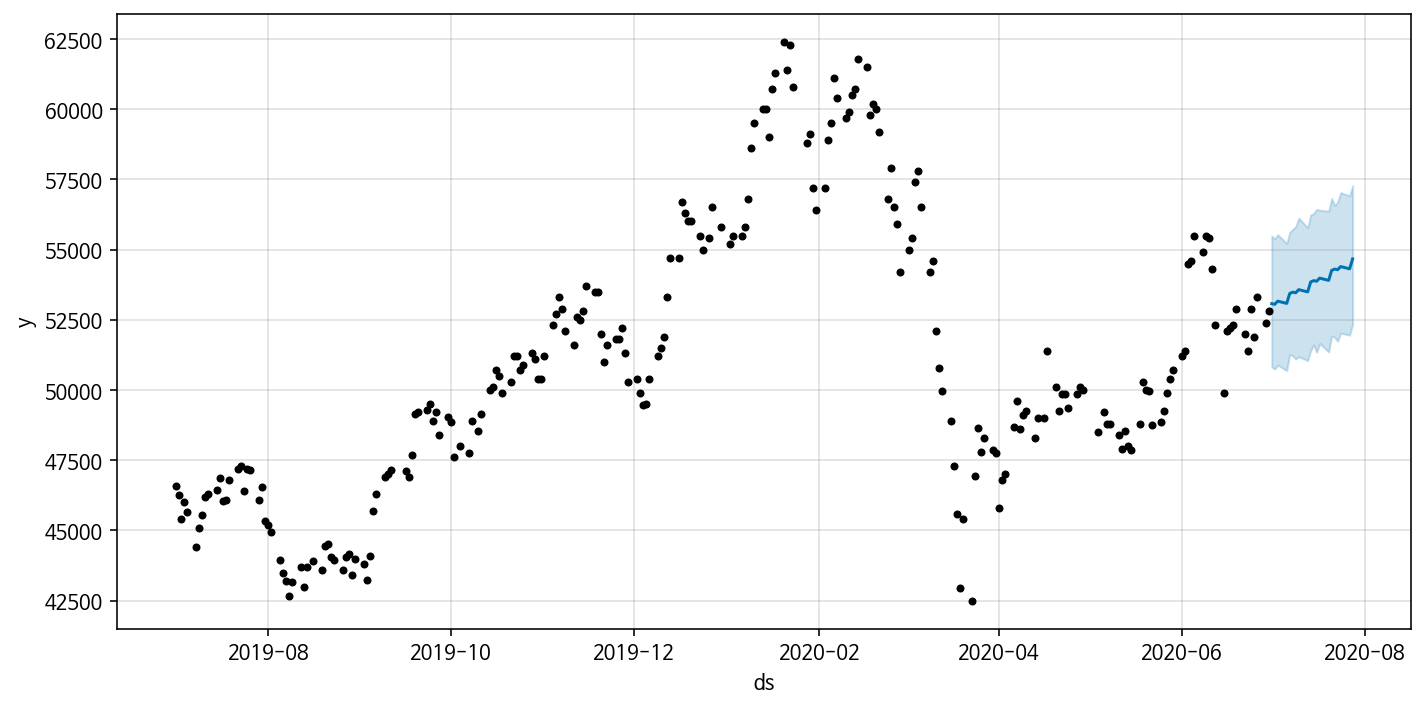
| metric | MAE | RMSE |
|---|---|---|
| Model 1 | 690 | 1115.71 |
| Model 2 | 730.78 | 1034.13 |
| Model 3 | 782.01 | 1080.23 |
| Model 4 | 751.8 | 1110.72 |
- MAE: MAE는 오차들의 절댓값의 평균이다. MAE의 장점은 outlier에 비교적 덜 민감하고 robust하다는 것이다.
- RMSE: RMSE는 보통 회귀 모델의 평가 metric으로 많이 쓰이는데, 오차제곱의 평균을 나타낸다. RMSE는 overfitting 여부를 판단할 때 유용하지만, outlier에 민감하다.
본 분석은 regression에 가깝기 때문에 MAE보다 RMSE가 더 유용한 지표라고 판단한다. RMSE를 기준으로 Model 2가 가장 높은 성능을 보이며, 그 다음으로는 Model 3의 성능이 높다. 그 이유는 무엇일까?- Model 4는 필자가 삼성전자 주가 데이터의 트렌드를 최대한 많이 반영하고자 다양한 지표를 추가했다. 그 결과 기존 데이터에 overfiting되어 실제 예측을 진행했을 때는 성능이 비교적 좋지 않게 나왔다.(1110.72)
- Model 2와 Model 3는 적절히 트렌드도 잡아내면서 overfitting도 어느정도 방지하는데 비교적 성공한 모델처럼 보여진다.
여기서 삼성전자 주가 데이터에 Simple Prophet 모델을 적용한 결과에 대한 포스팅을 마무리하겠다. 동시에, 그동안 계속 이어오던 시계열분석 포스팅의 마무리이기도 하다! 나중에 시계열분석 기법이 더 익숙해져서 복잡한 모델링을 하게 되면 또 포스팅을 할 예정이다. (추가적으로 Prophet 모델의 장점 중 하나인 holiday 반영 성질을 사용하지 않았는데, 이는 주식 거래는 주말 및 공휴일에 이뤄지지 않기 때문에 아예 해당 날짜에 데이터가 없어서 사용하지 않았다.)
참고문헌
https://zamezzz.tistory.com/279
https://predictor-ver1.tistory.com/4
https://hyperconnect.github.io/2020/03/09/prophet-package.html
댓글남기기