
[Time Series Analysis] #3. Simple Web Traffic Data Analysis - Part 1
Kaggle data에 시계열분석 적용해보기
Part 1. Data Cleansing & EDA
지금까지 시계열분석에 대한 필요성을 느끼고 KMOOC 강좌로 이론을 공부하고 블로그에 포스팅을 했었다. 이론만 공부해서는 실제로 시계열분석 기법들이 어떻게 적용되는지 공부하기 힘들다.
그래서 이번 포스팅부터는 Kaggle 데이터를 분석해보는 작은 미니 프로젝트를 진행해보려고 한다.
포스팅은 다음과 같은 두 단계로 나누어서 진행할 예정이다.
- Part 1. Data Cleansing & EDA
- Part 2. ARIMA
이번 포스팅인 Part 1에서는 기본적인 데이터 처리 및 이해를 위한 Data Cleansing 과 EDA 과정을 다루겠다!
Web Traffic data 개요
- link: https://www.kaggle.com/c/web-traffic-time-series-forecasting/data
- 145063 rows, 551 columns
- rows: access 방법, agent 종류를 포함한 위키피디아 page name
- columns: 2015년 7월 1일부터 2016년 12월 31일까지의 일 단위
- values: Page 방문자 수
 보다시피 데이터의 크기가 너무 크기 때문에 필자는 Page 중 ‘en.wikipedia.org’를 포함하는, 즉 영문 위키피디아 페이지만을 대상으로 분석을 진행했다. 그리고 날짜 또한 2016년 날짜만
포함하는 방향으로 진행했다.(2016년 1월 1일 ~ 2016년 12월 31일)
보다시피 데이터의 크기가 너무 크기 때문에 필자는 Page 중 ‘en.wikipedia.org’를 포함하는, 즉 영문 위키피디아 페이지만을 대상으로 분석을 진행했다. 그리고 날짜 또한 2016년 날짜만
포함하는 방향으로 진행했다.(2016년 1월 1일 ~ 2016년 12월 31일)
1. Data Cleansing
(1) 데이터 재구조화
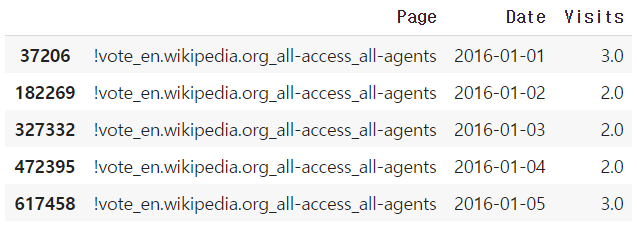
Raw data 를 보면 row가 Page 명, column이 일별 날짜로 이루어져있는데 이를 그대로 쓰게 되면 데이터를 분석하기 다소 힘들다는 판단을 했다. 따라서 pd.melt 를 이용해 데이터재구조화를
진행했다. 재구조화는 Column을 이루는 날짜들을 변수로 변환하여, Page별 일별 Visits 수를 나타내는 방향으로 진행했다. Date 변수가 본래 column 에 있던 날짜들을 나타낸다. 결과는 아래와 같다.
(2) Missing values 처리
본격적인 분석에 앞서 정제한 데이터가 missing value를 포함하고 있는지를 확인한다. 그 결과 Visits 변수에서 missing의 약 5.3%의 비율로 발생했다. Kaggle 홈페이지의 data 설명을 보면
missing value에 대해 다음과 같이 설명한다: A missing value may mean the traffic was zero or that the data is not available for that day.
[Missing valule 처리 방법]
- Missing value를 제거하면 한 날짜에 해당하는 데이터가 삭제되므로 시계열분석에 영향을 미칠 수 있기 때문에 제거하지 않는다.
- Missing value를 0 으로 처리한다. Description을 보면 traffic이 0인 경우 NaN 값으로 입력이 되어있다고 했고, traffic 이 available 하지 않았다는 것도 결국 Visits 수로 따지면 0이기 때문에 0으로 처리하는 것이 합리적이라고 판단했다.
- 예외: 2016년 1월 1일부터 2016년 12월 31일까지 모두 Visits가 0인 데이터는 향후 추세를 분석할 때 악영향을 미칠 수 있고, 미래의 Visits 수를 예측해도 0일 것이기 때문에 제거한다.
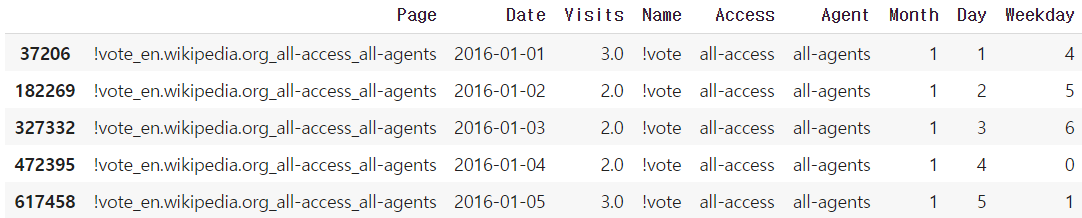
(3) Page 이름 나누기
Page 변수는 ‘AKB48_zh.wikipedia.org_all-access_spider’ 와 같이 ‘Page명_위키피디아국가주소_access방법_agent종류’ 의 형식으로 기록되어있다. Page 이름이 길기도 하고, 이름이 단일
구성이 아닌 여러가지 항목으로 구성되어있기 때문에 split을 이용하여 Page명을 나누고, Access와 Agent 라는 각각 access 방법과 agent 종류를 나타내는 파생 변수를 생성하였다. 또한
Page 명을 나타내는 Name 변수를 생성했다. 이와 같은 방법으로 처리를 한 후 각 변수에 속하는 unique 한 값의 개수를 세주었다.
Nameunqiue값 수: 6631Accessunqiue값 수: 3Agentunqiue값 수: 2
(4) Date format 처리
유연한 시계열분석을 위해 pd.to_datetime을 이용해 Date 변수의 속성을 datetime 으로 변경했다. 그리고 좀 더 세밀한 분석을 위해 Date 변수로부터 월(month), 일(Day), 요일(Weekday)
를 추출해 각각을 나타내는 새로운 변수를 생성했다.
이제 Data Cleansing 과정이 마무리되었다! Data Cleansing을 통해 정제된 final data는 다음과 같다.
2. EDA
Data Cleansing을 했으니 본격적으로 데이터를 탐색해보자! 우선 Page를 구성하는 요소들인(Data Cleansing (3) 참고) Access, Agent 에 대해 살펴보고 time series EDA를 진행한다.
(1) Access
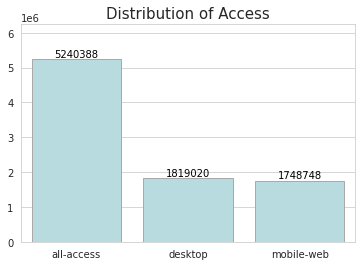
Access란 사용자가 wikipedia page에 어떻게 접근했는지를 나타내는 변수이다. Access 방법에는 총 세가지가 있으며 각각 all-access, desktop(컴퓨터접근), mobile-web(모바일접근) 을 나타낸다. 위키피디아 web traffic 중 all-access 로 접근한 고객이 가장 많으며, 그 뒤로 desktop, mobile-web 순서대로 많다.
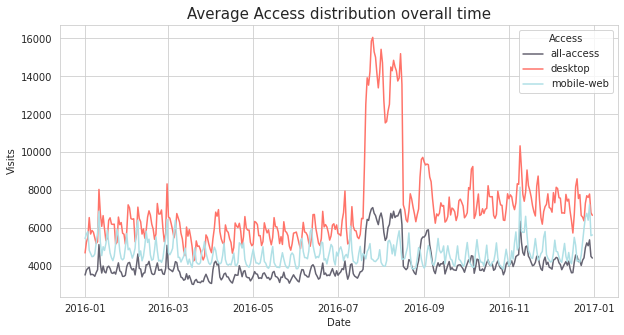
이제 Access 방법 마다 평균 Visits 수가 어떤 시계열적 패턴을 보이는지 분석해보자.
- 아래 plot을 보면 흥미로운 결과를 발견할 수 있는데, desktop을 통한 평균 방문자수가 2016년 7월과 8월에 급증하는 것을 볼 수 있다. Desktop 에 비해 눈에 띄지 않지만 이 기간에 all-access 를 통한 방문자수도 급증했다.
- 전체적으로는 desktop 을 통한 방문 수의 평균이 셋 중에 가장 높다. desktop 의 평균 Visits 수는 2016년 12월로 갈수록 전체적으로는 증가하는 추세를 보인다.
- mobile-web의 경우 뚜렷한 추세는 보이지 않지만 그래프가 일주일마다 같은 패턴을 반복하는 계절성을 띈다.
(2) Agent
Agent는 일종의 웹의 하수인 역할을 한다고 생각하면 된다. 구글에 검색에 따르면 Agent는 web traffic을 모니터링하는 역할을 한다. 본 분석에 사용한 Web Traffic data에서 agent는 크게 all-agent(일반웹접근), spider(웹크롤링) 로 구성되어있다.
위키피디아 트래픽 중 대다수는 all-agent를 통해 접속했고, spider 로 방문한 수는 all-agent 에 비해 현저히 적다.
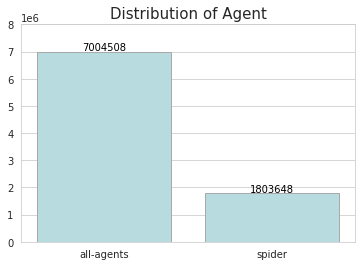
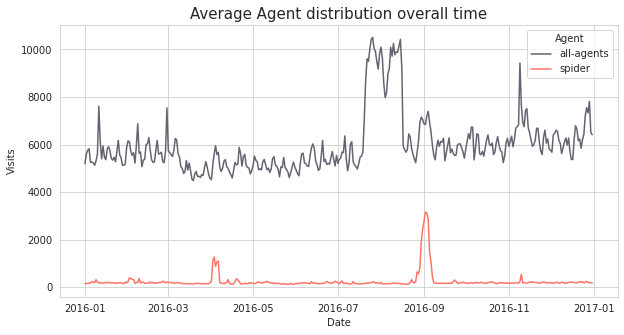
Access와 마찬가지로 일별 평균 방문자수 추이를 비교해보자. all-agent를 통해 방문한 수가 전체적으로 spider을 통해 방문한 수 보다 훨씬 높다. 한가지 특이한 점은 앞선 Access 분석해서
Access 방법별로 평균 방문 수가 전체적으로 큰 차이를 보이지 않았던 것에 반해, agent의 경우 all-access와 spider의 차이가 매우 크다.
그 이유는 무엇일까? Web Traffic 에서 spider는 웹크롤링을 하는 작업을 말한다. 일반적으로 유저가 웹에 접속할 때 크롤링을 통해서 접속하기 보다는 각 유저의 기기나 매체를 통해 직접
접속한다. 따라서 spider agent의 데이터 건수가 현저히 적고, 웹크롤링을 하면 그 페이지에 머무는 시간이 적기 때문에 아래와 같은 결과가 나온다.
(3) Time based 분석
전체 데이터의 시계열적인 trend를 파악하기 위해 일별, 월별, 요일별로 Visits 수의 평균을 내어 비교해보았다.
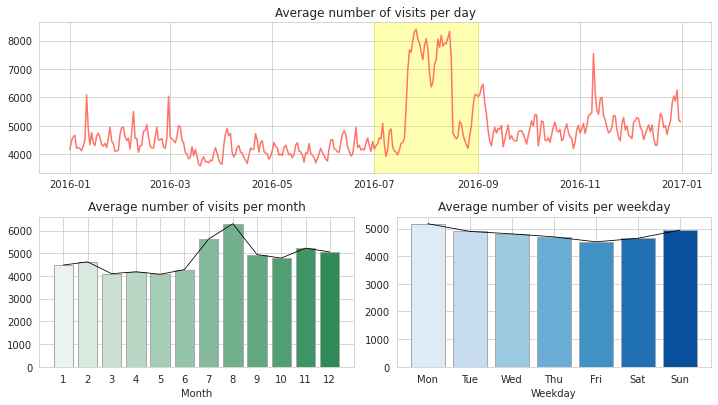
[해석]
- 일별 평균 Visits 수는 전체적인 증감 추세는 판별하기 힘들다.(뒷 포스트에서 자세히 다룰 예정!) 하지만 2016년 7월과 8월에 Visits 수가 급증했다. 앞서 Access 중 desktop에 해당하는
데이터와 비슷한 추이를 보인다.
- 7월과 8월에 급증한 이유를 추론하면 summer holiday season 이라는 이유를 생각할 수 있다. 여름 방학 시즌에는 학교나 회사보다는 집에서 보내는 시간이 많기 때문에 그만큼 web traffic이 급증한 것으로 보인다. (만약 이 추론을 보충설명할 수 있는 근거를 찾으면 포스팅하겠다!)
- 월별 평균 Visits 수의 추이는 일별 추이와 비슷하다. 이 역시 2월 이후에 최저점을 찍다가 7-8월에 급 반등을 시작했다가 9월부터 다시 하락한다.
- 요일별 평균 Visits 수는 월->금으로 갈수록 감소하다가 주말에 다시 반등한다.
- 이 역시 1번과 비슷한 이유로 생각할 수 있는데, 주중보다 주말에 집에 머무는 시간이 많기 때문에 반등한 것으로 예상할 수 있다.
3. Clustering
EDA 파트의 (3) Time based 분석 결과를 참고했을 때, 월별 평균 Visits 수 추이가 전체 추이와 비슷하기 때문에 월(month)를 기준으로 hierarchical clustering을 진행해보았다. Correlation을 이용하여 클러스터링을 하여 월별 추이가 비슷한 Page 끼리 그룹화하는 것을 목표로 했다. 결과적으로 Page를 총 11개의 클러스터로 그룹화하였다. (자세한 클러스터링에 대한 코드는 포스팅 마지막 링크에 첨부하겠다!)
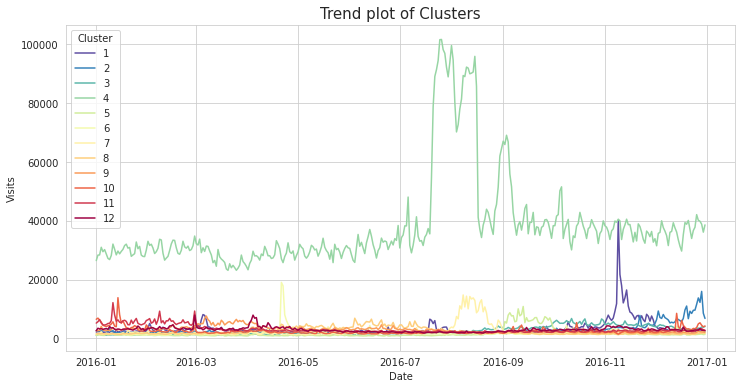
클러스터링 결과 대부분의 클러스터는 비교적 평균 Visits 가 낮았던데 반해 Cluster 4 에 해당하는 Page들의 추이를 보면 앞서 분석했던 (3) Time based 분석의 일별 추이와 비슷하다! 이를 통해 Cluster 4 에 속하는 Page들의 방문수가 대체적으로 다른 Page들에 비해 훨씬 높다는 결과를 얻을 수 있다.
Cluster 4에 속하는 Page의 속성을 몇 개 살펴보았는데 보통 ‘운동, 식물 등등’ 과 관련된 Page들이 많았다. 여기서 아쉬운 점은, web traffic data 에서 페이지의 속성 또는 페이지가 속하는 카테고리에 대한 정보를 갖고 있지 않기 때문에 어떤 카테고리가 web traffic 빈도가 높은지를 파악할 수 없다는 것이었다!
이번 포스팅은 여기서 마무리하겠다. 데이터의 크기가 너무 크고, 정제되지 않은 형태라 처음에 많이 당황했지만 여러가지 소스를 찾고 생각을 해보면서 분석을 할 수 있었다! 다음 포스팅에서는 이 데이터에 시계열분석기법을 적용하는 연습을 해볼 것이다. 포스팅에 사용한 코드는 여기로 들어가면 된다.
참고문헌
https://www.kaggle.com/zoupet/predictive-analysis-with-different-approaches
https://en.wikipedia.org/wiki/Web_crawler
https://jlim0316.tistory.com/92
댓글남기기