
[CNN] #1. CNN의 기본 및 간단한 구현하기
이제부터 약 한 학기(6개월정도?) 동안은 딥러닝 관련 포스팅을 주로 해보려고 한다. 이번 학기에 딥러닝 강의를 듣기도 하고, 스스로 더 찾아보고 공부해보고 기록을 남기고 싶어서 시작하게된 딥러닝 포스팅! 첫번째 주제는 이미지 분류에 주로 이용되는 CNN(Convolutional Neural Network) 이다.
이번 포스팅은 CNN 포스팅의 첫 주자이기 때문에, CNN의 기본 이론을 간략히 리뷰하고 tensorflow를 이용해 simple한 모델을 구현해보는 것에 대해 다룰 것이다.
BASICS OF CNN
1. CNN 기초 이론 리뷰
cf) 본 포스팅에서는 CNN의 구조는 정말 간단하게 요약하고 코드 중심으로 다룰 예정입니다
(1) CNN의 구조
CNN은 크게 Convolutional layer, Pooling layer, Fully connected layer로 구성되어 있다. 기본적인 구조는 아래 그림과 같다.
이미지 데이터를 입력하면 우선 Conv layer에서 필터 연산을 거치게 되고 활성화함수를 통과한 후, Pooling layer에서 pooling된다. 그리고 이 구조가 여러번 반복된다. Output으로 내보내기 전,
Fully connected layer에서 이전까지 처리된 이미지 데이터가 1D array로 변형된다. 그 후 Softmax 계층을 통과하면서 각 class로 분류된다. 이제 하나씩 살펴보자!
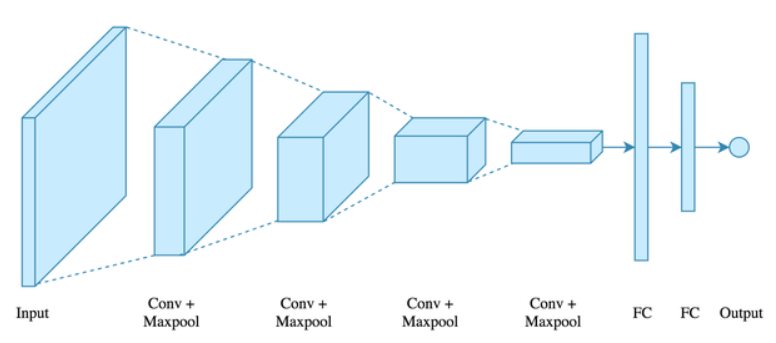
1. Convolutional layer
합성곱계층 Convolutional layer(줄여서 Conv layer)는 입력된 이미지의 특징(화소, 구성)을 반영하여 새로 처리된 이미지를 생성하는 계층이다. 합성곱계층에서는 이미지에 대해 필터연산을 수행하게 되는데 필터의 개수, 크기에 따라 이미지 연산이 달라지기도 한다.
2. Pooling layer
풀링 계층은 합성곱 계층을 통과한 이미지의 대표적인 픽셀만 뽑는 역할을 한다. 대표적인 pooling 방법에는 max pooling, global mean pooling이 있는데 일반적으로 CNN에서는 max pooling을 많이 사용한다. (Max pooling은 n x n 픽셀에서 가장 큰 값만 추출한다.) Pooling의 장점은 다음과 같다.
- 이미지 데이터의 크기가 줄어 CNN에서 계산량을 줄일 수 있고, complexity 또한 줄일 수 있다.
- 이미지의 국소적인 영역에서는 픽셀의 위치가 바뀌어도 pooling 결과는 동일하기 때문에 이미지를 구성하는 요소가 바뀌어도 CNN의 출력값이 영향을 받지 않는다.
3. Fully connected layer
완전연결계층에서는 앞에서 모든 처리를 거친 이미지 데이터를 1D array로 변환하여(flatten) softmax 함수를 적용할 수 있게끔 변환한다.
(2) 기본 처리
- filter size: 합성곱 계층에서 가장 핵심적인 필터의 크기를 나타내는 것으로, 필터 사이즈에 따라 output image의 사이즈가 달라진다.
- fiter 개수: 필터 개수는 output image의 채널 수를 결정한다.
- padding: 기존 이미지 주변을 특정 값(보통 0)으로 채우는 과정으로, 합성곱 계층을 통과해도 이미지의 사이즈가 감소하는 것을 방지하기 위해 사용한다.
- stride: 합성곱 계층에서 필터가 이동할 때, 처리 후 몇칸을 이동할지를 결정하는 것으로 이 역시 output image의 사이즈를 결정한다.
2. Simple CNN 구현 코드
이제 CNN을 tensorflow를 이용해서 구현하는 방법에 대해서 알아보겠다. 사용한 데이터는 아주 유명한 데이터인 MNIST 손글씨 데이터이다.
(1) Load MNIST data and preview
tensorflow.keras 에서 datasets를 이용하면 MNIST 데이터셋을 불러올 수 있다. 데이터 구성은 다음과 같다.
- train images: 이미지 데이터 600000개, 이미지 크기 28 x 28
- test images: 이미지 데이터 100000개, 이미지 크기 28 x 28
- class 수: 10개(0~9)
# MNIST 데이터 로드
(train_img, train_labels), (test_img, test_labels) = datasets.mnist.load_data()
만약 이미지 데이터 중 일부를 미리 보고 싶다면 matplotlib의 imshow를 이용하면 된다.
# imshow를 이용해 MNIST 이미지 세개 미리보기
fig, ax = plt.subplots(nrows = 1, ncols = 3)
for i in range(3):
ax[i].imshow(train_img[i])
plt.tight_layout()
plt.show()
그러면 다음과 같이 이미지를 미리보기 할 수 있다.

(2) CNN Model
이제 본격적으로 tensorflow를 이용하여 CNN 모델을 구축해보자. 주피터 노트북 또는 colab에서 tensorflow를 사용하기 위해서는 우선 pip install tensorflow를 이용해 설치를 해야한다.
로드해야할 함수는 다음과 같다.
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
from keras.utils.np_utils import to_categorical
# CNN 모델 위한 필수적인 layer
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
Modeling process
Sequential()을 이용해 layer을 쌓기 위한 틀을 만든다.Conv2D를 이용해 합성곱계층을 구현한다- filters: 필터 개수
- kernel_size: 필터(커널) 사이즈 ex) (3, 3)
- strides: stride 크기(몇 칸 띄어서 필터링할지 결정). 기본값은 (1, 1)
- padding: ‘same’(합성곱계층 거쳐도 input 이미지의 사이즈 유지되도록 패딩), ‘valid’(패딩하지 않음)
- activation: 활성화함수 지정
- input_shape: input 이미지의 shape
MaxPool2D를 이용해 max pooling layer을 구현한다.- pool_size: max pooling layer의 사이즈
- strides: stride 크기
Flatten으로 Fully connected layer 구현. 2D tensor을 1D array로 알아서 변환해준다!- 1차
Dense를 이용해 FC layer을 Dense에 통과시켜 activation function을 적용한다.- Dense layer node 수 지정하기
- 2차
Dense를 이용해 softmax 함수로 출력할 output layer을 만든다.
이제 MNIST 데이터셋에 적용할 CNN 모델 코드를 작성해보자. 각 코드에 대한 설명은 주석으로 첨부하였다.
첫번째 모델의 구조: Conv -> Conv -> MaxPooling -> Conv -> Conv -> MaxPooling -> FC -> Dense -> Dense(softmax)
# 이미지 데이터 reshape -> (데이터 수, 픽셀 가로, 픽셀 세로, 채널 수)
train_img = train_img.reshape((60000, 28, 28, 1))
test_img = test_img.reshape((10000, 28, 28, 1))
# 이미지 데이터 표준화
train_img, test_img = train_img/255, test_img/255
# labels one-hot encoding(카테고리 데이터 인코딩)
train_labels = to_categorical(train_labels, num_classes = 10)
test_labels = to_categorical(test_labels, num_classes = 10)
# Modeling
model = Sequential()
# Conv2D layer 1
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu', input_shape = (28, 28, 1)))
# Conv2D layer 2
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu'))
# MaxPooling layer 1
model.add(MaxPool2D(pool_size = (2, 2)))
# Conv2D layer 3
model.add(Conv2D(filters = 64, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu', input_shape = (28, 28, 1)))
# Conv2D layer 4
model.add(Conv2D(filters = 64, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu'))
# MaxPooling layer 2
model.add(MaxPool2D(pool_size = (2, 2)))
# Fully connected layer
model.add(Flatten())
# Dense layer
model.add(Dense(256, activation = 'relu'))
# Output
model.add(Dense(num_classes, activation = 'softmax'))
이렇게 모델을 구축하고 model.summary()를 이용하면 model의 구조와 사용된 파라미터의 수를 한 번에 볼 수 있다.
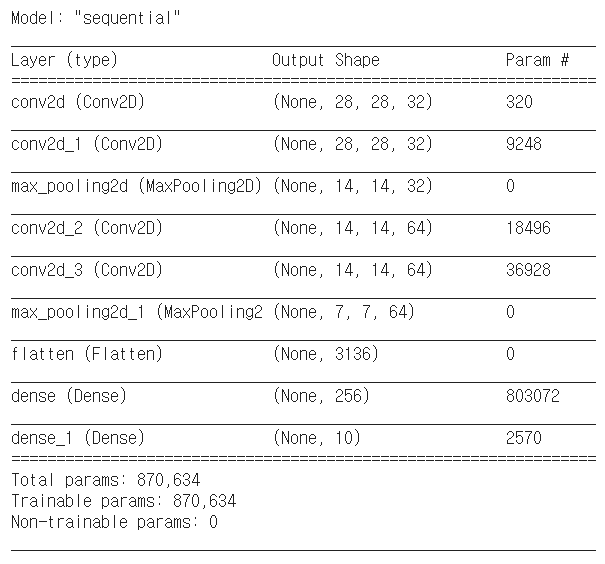
Question) 각 layer에 사용된 파라미터 수는 어떻게 결정될까?
간단히 생각하면 된다! 첫번째 합성곱 계층을 예시로 들어보자.
Input 이미지의 shape은 (28, 28, 1)로 채널 수는 1개이다. 즉 채널이 1개이기 때문에 Conv2D layer에서 (3, 3) 커널이 1쌍 필요하다. (채널이 3개이면 (3, 3) 커널이 3개 필요)
여기에 bias term까지 포함하면 모수는 (3 x 3 x 1 + 1) 개가 필요한데, 필터(커널)을 총 32개 사용했으므로 추가적으로 32개를 곱하면 (3 x 3 x 1 + 1) x 32 = 320 개의 파라미터가 필요한 것이다!
간단하게 합성곱계층에서 사용되는 파라미터 수를 공식으로 나타내면 다음과 같다:
(커널사이즈 x 커널사이즈 x input data 채널 수 + 1) * 사용된 필터 수
(3) Model compile & Model 학습
1) Compile CNN model을 구축한 후 학습을 하기 위해선 model compile을 해야한다. Model compile 단계에서는 optimizer, loss, 평가 metric, batch size 를 지정해준다. 이번 포스팅은 아주 기본적인 CNN 모델만 다루기 때문에 batch size는 다음 포스팅에서 자세히 다루도록 하고 나머지만 적용하도록 하겠다!
- optimizer: Adam (가장 성능이 높다고 알려진 Adam 사용)
- loss: categorical_crossentropy (label이 카테고리형 자료이기 때문에 사용)
- metric: accuracy
2) 학습
fit 메소드를 사용하여 진행한다. input으로는 train 이미지, labels을 받고 validation_data에는 model validation을 진행할 데이터셋을 입력해주면 된다.
- epochs: 전체 데이터를 학습하는 과정을 몇 번 반복할지를 설정
- verbose: model 학습 과정을 창에 나타낼지를 설정 (0 = silent, 1 = progress bar)
# model compile
model.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
# 모델 학습(history에 결과 저장)
history = model.fit(train_img, train_labels, epochs = 5, validation_data = (test_img, test_labels), verbose = 1)
(4) 결과 비교
history를 이용해 모델링 결과값을 비교할 수 있다.
- history[‘accuracy’]: train set 정확도(accuracy)
- history[‘val_accuracy’]: validation set 정확도
- history[‘loss’]: train set loss(categorical crossentropy)
- history[‘val_loss’]: test set loss(categorical crossentropy)
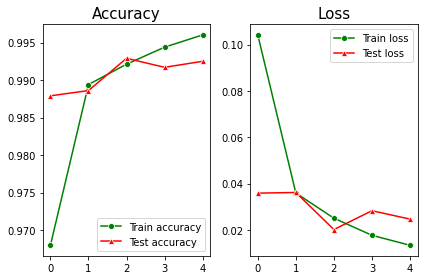
그래프를 보면 train 과 validation set의 accuracy와 loss가 크게 차이나지 않기 때문에 overfitting이 적게 일어난 것을 알 수 있다. 딥러닝에서 overfitting 문제를 해결하기 위해
Dropout layer 을 사용하기도 하는데, 이것에 대해서는 다음 포스팅에서 다루도록 하겠다.
여기까지 CNN의 구조를 간단하게 리뷰하고 가장 simple한 CNN 모델을 구축해보았다. 다음 포스팅에서는 모델을 더 develop하기 위한 방법들을 소개하겠다 :)
참고문헌
https://www.tensorflow.org/tutorials/images/cnn?hl=ko
밑바닥부터 시작하는 딥러닝(한빛미디어)
댓글남기기