
[CNN] #2. CNN model - Dropout Layer
이전 포스팅에서는 가장 basic한 CNN 모델을 구현하는 방법에 대해 다루었다. 이번 포스팅에서는 CNN 모델을 보다 더 구체적으로 만드는 옵션들에 대해 살펴볼 것이다. 여러가지 옵션이 있겠지만, 이번 포스팅의 주제는 CNN 모델에서의 Dropout layer, batch size 이다. 관련된 논문 요약과 더불어 이 옵션들이 MNIST 데이터에 적용했을 때 모델 성능에 어떤 영향을 미치는지 알아보자!
Dropout Layer
(1) Dropout layer란?
Dropout layer은 말 그대로 딥러닝/CNN 모델에서 hidden layer(은닉층)에 있는 노드의 일부를 drop하는 layer이다. 보통은 “노드를 없애면 오히려 모델 성능이 떨어지지 않을까?” 라는 의구심을 품을 수 있다. Dropout layer가 모델의 성능을 높여준다는 보장은 없지만, 적어도 CNN 모델의 overfitting은 방지할 수 있다.
Overfitting(과적합)은 모델이 훈련 데이터셋를 과도하게 학습하여 훈련 데이터셋에 대해서는 모델의 성능이 좋지만 새로운 데이터셋(예를 들면 검증 데이터셋)에 대해서는 오히려 성능이 떨어지는 현상을 말한다. 좋은 모델이라면 어떤 데이터셋이 들어와도 잘 예측을 해야 하기 때문에 CNN 모델링에 있어서 과적합이 발생하지 않도록 하는 것은 매우 중요하다.
CNN을 포함한 딥러닝 모델에서는 과적합을 방지하기 위해 Dropout layer을 사용한다.
Dropout layer에 대한 대표적인 논문에 의하면 dropout layer이 과적합을 방지하는 이유는 다음과 같다.
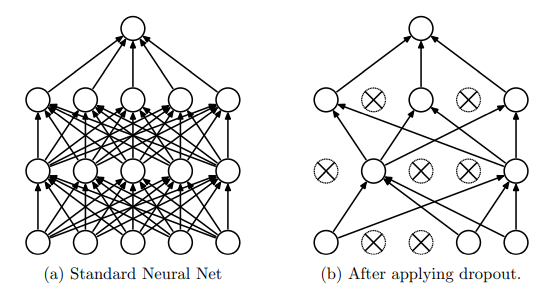
- 일반적으로 딥러닝 모델은 매우 복잡하기 때문에 모델끼리 앙상블(ensemble)을 하여 학습하는 것이 어렵다. 하지만 일부 노드를 랜덤하게 드랍하게 되면 노드의 수가 줄면서 복잡했던 딥러닝 모델이 보다 더 간단해진다. 따라서 다양한 딥러닝 네트워크를 앙상블 하는 것이 용이해진다. (일반적으로 모델 앙상블을 가능하면 모델의 분류/예측 성능이 높아진다는 것)
- Dropout은 co-adaptation 현상을 방지한다. 이미지 데이터의 각 픽셀은 Conv layer을 거치면서 다른 픽셀의 단점을 보완하는 방향으로 픽셀 값이 업데이트 된다. 이에 따라 복잡한 co-adaptation이 발생할 수 있는데, co-adaptation은 각 이미지 픽셀이 서로 의존하게 되면서 overfitting을 발생시킬 수 있다. 하지만 dropout을 하게 되면 각 픽셀이 서로에게 의존하는 정도가 감소하게 되면서 co-adaptation 감소시킴으로써 overfitting을 방지하게 된다.
- 논문에 의하면 은닉층에 있는 노드를 dropout 하는 비율은 0.5보다는 0에 가깝게 하는 것이 최적의 비율이라고 한다.
(2) MNIST 데이터에 적용
이제 MNIST 데이터셋에 Dropout layer을 추가하여 모델을 구현해보고 결과를 보자. 자료조사를 해보니 dropout layer을 모든 layer에 쓸 수 있는 것이 아니고, 마지막 output을 출력하는 layer에는 dropout을 적용하지 않는다.(사실 당연한 소리긴 하다)
Python에서 구현하는 방법은 간단하다. 이전에 Conv2D, MaxPool2D layer을 추가했듯이 model.add(Dropout(p)) 으로 dropout layer을 추가하면 된다. 괄호 안의 $p$는 해당 layer에서 몇 퍼센트의 노드를 드랍할 것인지를 결정한다. 만약 0.2를 입력한다면 랜덤으로 20%의 노드를 골라 드랍하는 것이다!
model = Sequential()
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu', input_shape = (28, 28, 1)))
model.add(Conv2D(filters = 32, kernel_size = (3, 3), strides = (1, 1), padding = 'Same', activation = 'relu'))
model.add(MaxPool2D(pool_size = (2, 2)))
# dropout layer 추가하기
model.add(Dropout(0.1))
Case1: 총 Dropout 비율 0.3
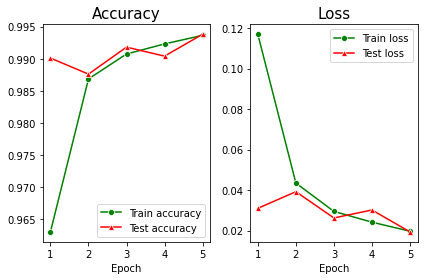
- Dropout을 한 결과, 하기 전에 비해 train accuracy와 test accuracy의 차이가 감소했다.(loss 도 마찬가지!)
- 따라서 dropout layer를 추가하면 모델이 overfitting 되는 경향이 감소하는 것을 확인할 수 있다.
Case2: 총 Dropout 비율 0.5
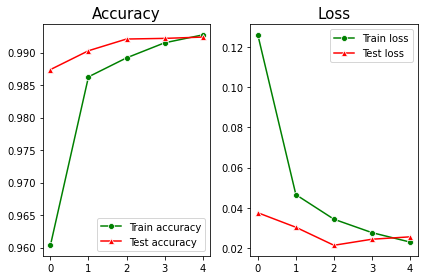
- 그래프를 보면 test accuracy가 train accuracy보다 높은 것을 확인할 수 있다. 기존에 학습한 데이터보다 새로운 데이터를 더 잘 학습한다는 뜻이기 때문에 overfitting은 방지했다고 해석할 수 있다.
- 하지만 accuracy 자체를 보면 총 dropout 비율이 0.3일 때보다 accuracy는 오히려 다소 낮아진 것을 확인할 수 있다. 이는 dropout 비율이 전체 노드의 절반(50%)이기 때문에 딥러닝 모델에서 잃은 정보가 많아 accuracy가 낮아졌다고 예상된다.
- 따라서 dropout layer을 추가하여 dropout은 하되, 그 비율을 줄여서 optimal한 모델을 만들 수 있도록 조정해야한다.
이렇게 CNN 모델에서의 dropout layer에 대해 알아보았다. 다음 포스팅에서는 batch size에 따른 MNIST 데이터셋을 적용한 CNN 모델 성능 비교를 할 예정이다 :)
참고문헌
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
댓글남기기