
[NLP] #1. 워드 임베딩(Word Embedding)
Prologue
자연어처리(Natural Language Preprocessing) 은 문장, 텍스트 등 인간의 언어를 컴퓨터 언어로 구현하는 AI 알고리즘이다. NLP는 현 시대를 대표는 AI 알고리즘 중 하나로, 가장 대표적인 것이 텍스트분석인데, 예를 들면 영화 감상평 분석, 트위터를 이용한 의견 분석 등등을 할 때 쓰이는 분석기법이다.

(이미지 출처: https://brunch.co.kr/@natrsci/83)
대학원 딥러닝 수업에서 처음으로 자연어처리에 대해 배웠는데, 공부할 것도 많고 알아가야 하는 것이 많아서 포스팅으로 남기려고 한다. 이 블로그에서 다루는 자연어처리 포스팅은 대부분 텍스트분석에 관련된 내용일 것 같다 :)
Word Embedding(워드 임베딩)
워드임베딩 은 텍스트를 구성하는 단어를 벡터로 표현하는 것이다. 쉽게 말하면, 단어를 밀집벡터(Dense vector)로 표현해 컴퓨터가 처리할 수 있게 변환하는 과정을 말한다. 본격적인 워드임베딩 방법론에 대해 다루기 전에 알아야 하는 용어들에 대해 살펴보자.
1. 희소벡터 vs 밀집벡터
희소벡터(Sparse Vector)
데이터분석에 대해 혹은 선형대수학을 공부했다면 희소행렬에 대해 들어보았을 것이다! 희소벡터(Sparse vector)도 비슷한 개념이다.
예를 들면 텍스트에서 “That dog is cute” 라는 문장이 있다고 하면, 이 문장은 the, dog, is, cute 의 네 단어로 이루어져 있다. 희소벡터는 각 단어가 있으면 1, 없으면 0으로 표현하는 것이다. 각 단어는 지정된 위치가 있다. 전체 텍스트에서 unique한 단어의 수가 8개라고 할 때 “The dog is cute”를 희소벡터로 나타내면 [0, 1, 0, 0, 1, 1, 0, 0, 1] 와 같다.
희소벡터는 곧 One-hot vector와 동일한 것이다. 데이터분석을 할 때 one-hot vector를 카테고리형 자료를 처리하는데 유용하다고 하지만 텍스트분석 시 이러한 표현 방법은 큰 단점이 있다.
- 단어의 수가 많아지면 벡터의 dimension이 매우 커져 분석에 어려움이 생긴다. (계산복잡도 증가, 공간 낭비)
- 전체 텍스트에서 한 번 등장한 단어도 벡터에 포함되기 때문에 텍스트 처리 시 비효율적이다.
밀집벡터(Dense vector)
밀집벡터는 희소벡터의 dimension 문제를 보완한 벡터이다. 밀집벡터는 말 그대로 희소벡터를 압축한 것으로, 희소벡터가 전체 텍스트에 포함된 단어의 수를 벡터의 크기로 정하는데 반해 밀집벡터는 사용자가 설정한 벡터의 크기로 단어를 맞춘다.
“The dog is cute”를 희소벡터로 나타내면 [0, 1, 0, 0, 1, 1, 0, 0, 1] 이지만, 밀집벡터로 나타내면 [0.2, -0.1, 0.03, 0.5] 와 같다.
2. Word2vec
Word2vec은 워드임베딩 방법 중 하나이다. 워드임베딩은 텍스트를 밀집벡터(Dense vector)의 형태로 변환하는 과정을 말한다. Word2vec에는 크게 CBOW와 Skip-Gram 이 있다. 이 두 방법은 Input과 output이 서로 반대일 뿐, 나머지 과정은 모두 동일하다.
(1) CBOW
CBOW는 주변단어를 이용해 중심단어를 예측하는 방법이다.
예시: A fat dog ate delicious meat
여기서 예측하고자 하는 중심단어가 ate라고 하자. CBOW에서는 window 라는 것을 결정하는데, 이는 중심단어 앞/뒤로 몇 개의 단어를 주변단어로 포함시킬지를 결정하는 요소이다. 만약 window가 2라면 ate 앞의 두 단어 fat, dog와 뒤의 두 단어 delicious, mean이 중심단어이다. 즉, $2 \times \text{window}$ 만큼 중심단어의 개수를 정한다.
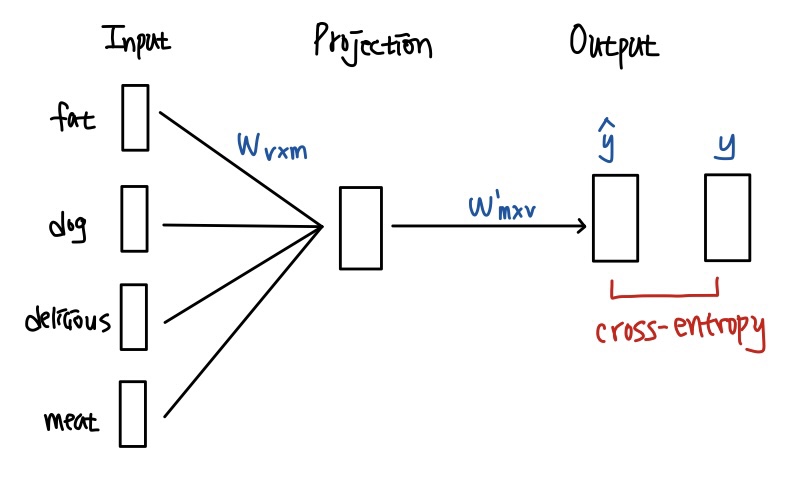
아래 그림은 CBOW의 매커니즘을 도식화한 것이다.
- Input layer: 주변단어 4개($1 \times v$ vector)를 input으로 받는다. 이 떄 가중치행렬 $W_{v\times m}$ 을 각 단어에 곱하여 그 값을 projection layer에 전달한다. 이 때 주변단어는 희소벡터 형태로 표현된다.
- Projection layer: 4개의 주변단어와 가중치행렬을 곱하여 4개의 output($1 \times m$ vector)을 산출한다. 이 때 각 output을 $v_{fat}, v_{dog}, v_{delicious}, v_{min}$이라 하자. Projection layer에서는 이 네 개의 벡터의 평균을 구하여 벡터 $v = \frac{v_{fat}+v_{dog}+v_{delicious}+ v_{min}}{2*\text{window}} $ 를 만든다.
- Output layer: Projection layer에서 구한 벡터 $v$와 가중치행렬을 transpose한 $W^\prime$ 행렬을 곱하여 output layer의 input으로 전달한다. 이 값을 $z$ 라 하자. 그리고 최종적으로 output layer의 ouput은 $z$에 softmax함수를 적용하여 구할 수 있다.
- Output layer에서 구한 최종 output $\hat{y}$와 예측하고자 하는 대상인 ate의 희소벡터 $y$ 와의 cross entropy를 계산하여 loss를 구한다.
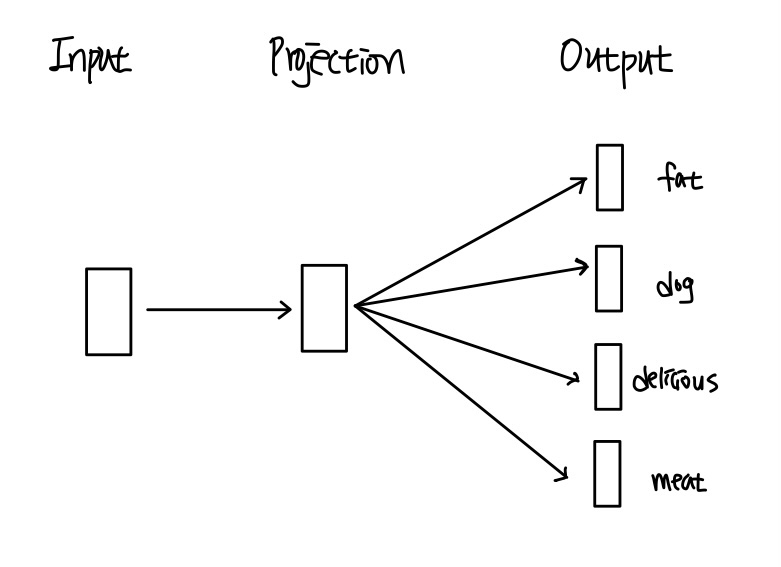
(2) Skip-Gram
SKip-Gram은 중심단어를 이용해 주변단어를 예측하는 방법으로, 앞서 다룬 CBOW 방법과 반대 과정이다. CBOW 방법과의 차이점 중 하나는 Skip-Gram 방법은 Projection layer에서 해당 layer의 output의 평균을 낼 필요가 없다는 것이다. 생각해보면 당연한 것인데 Skip-Gram 방법은 하나의 중심단어로 주변단어들을 예측하는 알고리즘이기 때문에 Input layer에서 Projection layer로 전달되는 값이 단 하나이므로 평균을 내지 않아도 된다.
2. GLOVE
텍스트분석 시 텍스트를 컴퓨터 언어로 처리하기 위해 사용되는 기법은 크게 카운트 기반, 예측 기반으로 나눠진다. 카운트기반은 말 그대로 텍스트를 구성하는 단어의 수를 세어 빈도를 기반으로 단어를 예측하고자 하는 것이고 예측기반의 대표적인 알고리즘은 이 포스팅에서 다룬 word2vec 이다. 이 두 방법론에는 장단점이 있다.
카운트 기반 방법론의 경우, 전체 텍스트에서의 단어 발생 빈도와 같은 전체적인 통계 정보를 포함하지만 단순히 “빈도 기반”이기 때문에 단어 간의 유사도를 반영하지 못한다는 단점이 있다. 반대로 예측 기반 방법론에서는 단어간 유사도를 반영하지만 전체 텍스트에서의 통계 정보는 반영하지 못한다.
이 두 방법론을 모두 사용하는 알고리즘이 바로 GLOVE 이다.
(1) 동시등장행렬(Co-occurence Matrix)
동시등장행렬은 텍스트를 구성하는 단어들을 행, 열에 배치하고, i번째 행에 해당하는 단어의 윈도우 크기 내에서 k 단어가 등장한 횟수를 표시한다. 백문이 불여일견! 예시와 함께 살펴보자.
예시: I like deep learning. I like NLP. I enjoy eating. 이렇게 세 문장이 텍스트를 구성한다고 하자. 그러면 텍스트를 구성하는 개별 단어는 I, like, enjoy, deep, learning, NLP, eating이다. 윈도우 사이즈는 1이라고 가정하자.
이를 동시등장행렬로 표현하면 다음과 같다.

위 표에서 I 단어를 살펴보자. I 단어의 윈도우 사이즈 1 내에서, 즉 바로 다음에 오는 단어는 like가 2개, enjoy가 1개이다. 따라서 I 행렬에 [0, 2, 1, 0, 0, 0, 0] 로 표시되는 것이다.
(2) 동시등장확률(Co-occurence Probability)
동시등장확률 $P(k|i)$는 $i$ 단어가 등장했을 때 윈도우 사이즈 내에서 $k$ 단어가 등장한 확률을 계산한 값이다. 위에서 다룬 동시등장행렬에 적용하면 $P(k|i)$는 $i$ 단어에 해당하는 행에 해당하는 카운트 값들을 모두 더한 것을 분자로 하고, $i$번째 행 $k$열에 해당하는 단어에 대한 카운트를 분모로 한다고 볼 수 있다.
이렇게 구한 동시등장확률을 이용해 손실함수를 구하고, 이 손실함수를 최소화하는 방향으로 NLP모델을 학습한다.
(3) GLOVE의 단점
- 텍스트를 구성하는 단어의 수가 증가하면 동시등장행렬의 크기가 증가하여 고차원 matrix가 될 수 있다.
- 전체 텍스트에서 한 번만 등장하는 단어가 많으면 행렬에 0 값이 많아져 sparsity 문제가 발생할 수 있다.
댓글남기기